Poisson Process
Until now, we have been considering only discrete-time markov chains. Here, we relax that assumption and talk about a continuous-time markov chain.
Motivation
In the real world, we often have to count the frequency of occurences of an event in a given time interval. For example:
- Number of flight passengers arrived until time
- Number of vehicles which passed a given location, until time
We may also use this “counting” process to make decisions. For example, if we want to determine whether we need to build more ICU units in the hospital, we can ask the following questions:
- How many new patients will need ICU until every time point ?
- How long will every patient need an ICU for?
And using the above information, we can come to a conclusion.
In the above examples, the state space is (discrete).
Let denote the quantity of interest until time , then is continuous (time index).
We’re only going to look at a special case of the continuous-time, discrete-state process: the Poisson process.
The Poisson Distribution
We begin with a fixed . In the time interval , we’re interested to know how many evens happen?
For such a problem, we know the poisson distribution if a good approximation. Why? We can explain it as follows:
- Because we can decompose into many many small disjoint intervals. Then, on each interval , the number of events follows . Why? Because the intervals are so tiny that it’s almost impossible for 2 events to happen in that time. It can either be 0/1, which is precisely what a distribution can model. And we write “” because it clearly depends on → if is large (so we have smaller intervals), then is (naturally) smaller and vice versa.
- We can sum together all the small intervals and then the number of events follows (assuming that all intervals are independent, and is the same for every interval). When and such that their product , then is a good approximation of .
By definition, a random variable is said to have a Poission distribution with parameter , denoted by , if its probability mass function is defined by:
We can show that the is a good approximation of as follows:
- When , given , using the definition of binomial distribution we have:
As , both and are very large. We can use stirling’s approxiamation which says that for large values of , we have: . The ratio is approximately for large enough (i.e., they cancel out). Hence,
Also, for large , we can approximate .
At the same time, we recall that the binomial expansion of is given by:
In our equation, and so, all higher order terms of in the expansion will be even smaller (and we can ignore them).
Combining the above simplifications, and assuming that is a moderate constant we can write:
which is the PMF for the poisson distribution.
Some Remarks
For the poisson distribution, the mean is and the variance is also (wow!)
The probability generating function PGF for Poisson Distribution is . We can use the PGF to prove the properties below as well.
If we have 2 independent poisson variables, and , then . Moreover this can be generalised to independent variables too.
The above result can be understood quite intuitively. We can see view this from two perspectives:
- Variables measuring different events in the same time period → Let’s say we have two independent random Poisson variables for requests received at a web server in a day: = number of requests from humans/day, and = number of requests from bots/day, . Since the convolution (aka sum) of Poisson random variables is also a Poisson we know that the total number of requests is also a Poisson: .
- Variables measuring the same event in different time periods → If is the number of events in a time interval of length , then is the number of (the same) events in an interval of length .
If and then .
Intuition: counts the frequency of events in the interval. adds another “thinning” factor to determine whether we should really count it or not. It’s a two-stage process. Think of it as taking only fraction of the actual events for every event that occurs, it has probability of being counted by .
Example: say we want to count the number of buses passing a given location, is the average number of vehicles per hour, and is the probability of a vehicle being a bus, then we can count the total number of buses per hour by using (as defined above using the two-stage process). Clearly, it is equivalent to defining a new variable where is the average number of buses crossing the location per hour.
Read a great explanation here 🎉
Proof of (4) using PGF
We will show that the must be by showing that its PGF is of that form.
The PGF for is (by definition of PGF, not using the fact that is poisson since that is what we’re trying to prove):
Also, recall that the PGF for binomial distribution is .
Given , is a binomial variable so we can write:
where the expectation is over .
Moreover, . So, the RHS of the above equation is just .
Then,
Now, we know that and so, . Using this in the above equation, we get:
It is clear that is the PGF of a variable. Hence, is a variable. QED
The Poisson Process
There are 3 ways we can choose to define the poisson process, and we discuss all of them (for the sake of understanding it better).
Def 1: Defining from the Poisson Distribution
The poisson distribution gives us the number of events in a fixed time interval .
Now, we want to be able to find the number of events for any time point .
We hope that our process satisfies the following:
- At each time point, #events in follows a poisson distribution.
- On disjoint time points, the number of events is are independent (so that their sum is still poisson).
- On different time intervals, the parameters are somewhat related (so that they’re describing a “process”, and not just a collection of random variables)
This is precisely the definition of the poisson process.
💡 A poisson process with rate, or intensity, is an integer-valued stochastic process for which
For any time points , the process increments
are independent random variables.
For and , the random variables
Basically, the distribution of the number of events on any time interval follows a distribution. And this is the same for all time intervals. That is, is the common/shared rate/intensity parameter.
We define to be the average number of events in one time unit (i.e., when , we have that the interval of unit time follows → events on average in unit time).
We can interpret the common as such: the distribution of number of events in a given time interval does not depend on the starting time, but only on the length of the interval itself! If we have two time intervals and such that , then the dsitribution on both the intervals follows .
In particular, we also have distribution for every fixed time point because we define for all .
It’s actually quite intuitive → the number of events in will be independent of that in because they are disjoint.
Moreover, the average number of events in any time interval of length increases linearly with , i.e., (and so is the variance).
Another corollary of the “common rate” property of a poisson process is that, the distribution remains unchanged when you shift the time point by any amount. For example, you start measuring the number of vehicles passing a given location at 8am, and they follow a poisson process (denoted by ) with parameter . Suppose another observer also comes to the location at 10am and starts counting vehicles - of course, his “process” is going to be different, but it will follow the same probabilistic structure of because nothing has changed except the “starting time”, and the poisson process doesn’t depend on that (because of the common rate throughout all eternity ).
This would not be true if the rate parameter changes over time → it’s more realistic that you see more cars from 8am - 10am since people are going to work and then, there are fewer cars from - 5pm, then more cars again from 5pm to 8pm since people are coming back from work. In such a scenario, itself varies with , and we do not have a poisson process (and here, the starting time definitely matters). We may still have poisson distributions on separate intervals (e.g. 8-10am, 10am-5pm, 5pm-8pm) but every interval enjoys its own .
Def 2: Building the process by small time intervals and the law of rare events
We now look at the poisson process from another viewpoint (to find another intuitive explanation).
Recall that we care about the poisson distribution mainly because it can be seen as an approximation of .
And, we like because we can decompose (for a fixed ) into disjoint time intervals and then, what happens in each time interval is independent with other intervals. In each time interval, the number of events . This is very small (this is the assumption we make when we use the poisson approximation, ) so small that we do not need to consider that there can be more than 1 event in that time interval. These events are called rare events.
The poisson process has a similar setup of rare events.
Law of Rare Events
Let be independent Bernoulli random variables where , and let . The exact probability for and the poisson probability with differ by at most
Remarks
- Notice that the ’s can be different → each bernoulli variable enjoys its own parameter .
- The above theorem asssures us that our poisson approximation to the binomial is “good enough” when the ’s are uniformly small enough. For instance, when , the right side reduces to , which is small when is large.
- Basically, the law of rare events states that if the process satisfies the rarity (small probability of event occuring on an interval), then its close to the poisson distribution.
We can then define a poisson process using the law of rare events as such:
Let be a RV counting the number of events occurring in the interval . Then, is a poisson point process of intensity if
For any time points , the process increments
are independent RVs.
There is a positive constant for which the probability of at least one event happening in a time interval of length is
where is any function that goes to zero faster than , i.e., . For example, will always be smaller than as .
noteRecall this is essentially the same definition (but reversed 😲) as little-O notation covered in CS3230 (but there, we defined it to mean that is a function that grows slower than when )
The probability of 2 or more events occuring in an interval of length is as (and this called a rare event)
Basically, we can write it as such: as ,
And under the limit , we can see that majority of the probability is concentrated at , i.e., it is very very unlikely for any event to occur in such a small time interval.
This definition is more useful in practice - given a set of data, we can easily check whether it satisifies the above properties of rare events. It’s much harder (and difficult to justify) why you think the data has a poisson distribution (so the first definition is quite hard to apply to real world data).
Def 3: Relationship Between Poisson and Exponential Distribution
Now we have introduced 2 definitions of the poisson process.
But can we simulate a poisson process according to the current results? It’d be very difficult. How would we simulate “rare events” or “” for any ? This is imposisble because is continuous! (how would you “record” the path of the poisson process for every value of in a computer when is continuous - that’s the difficulty).
We have to explore more properties of the process to propose a reasonable simulation algorithm.
Observe that for a poisson process, to record the entire path (even on continuous ), it suffices to only record the values of at which an event occurs! 😲 Knowing when the events occur is enough to completely describe a poisson process.
So, we only need the times at which the events occur in a poisson process. We’re now interested in how do we find these times. That is, how do we simulate when an event ocurs? (note that this is a fundamentally different question than sampling the poisson process directly because previously, we would have to decompose “time” into many small intervals, simulate a bernoulli RV for each interval, and see whether an event occurs or not → now, instead of thinking from the perspective of every time interval, most of which do not have any event anyway, we think from the perspective of the events themselves, and try to simulate when they will occur!)
Let be a poisson process with rate . Let be the time of the occurrence of the -th event, then it is called the waiting time of the th event. We always set .
The time between two occurrences are called sojourn times. measures the duration that poisson process sojourns (temporarily stays) in state .
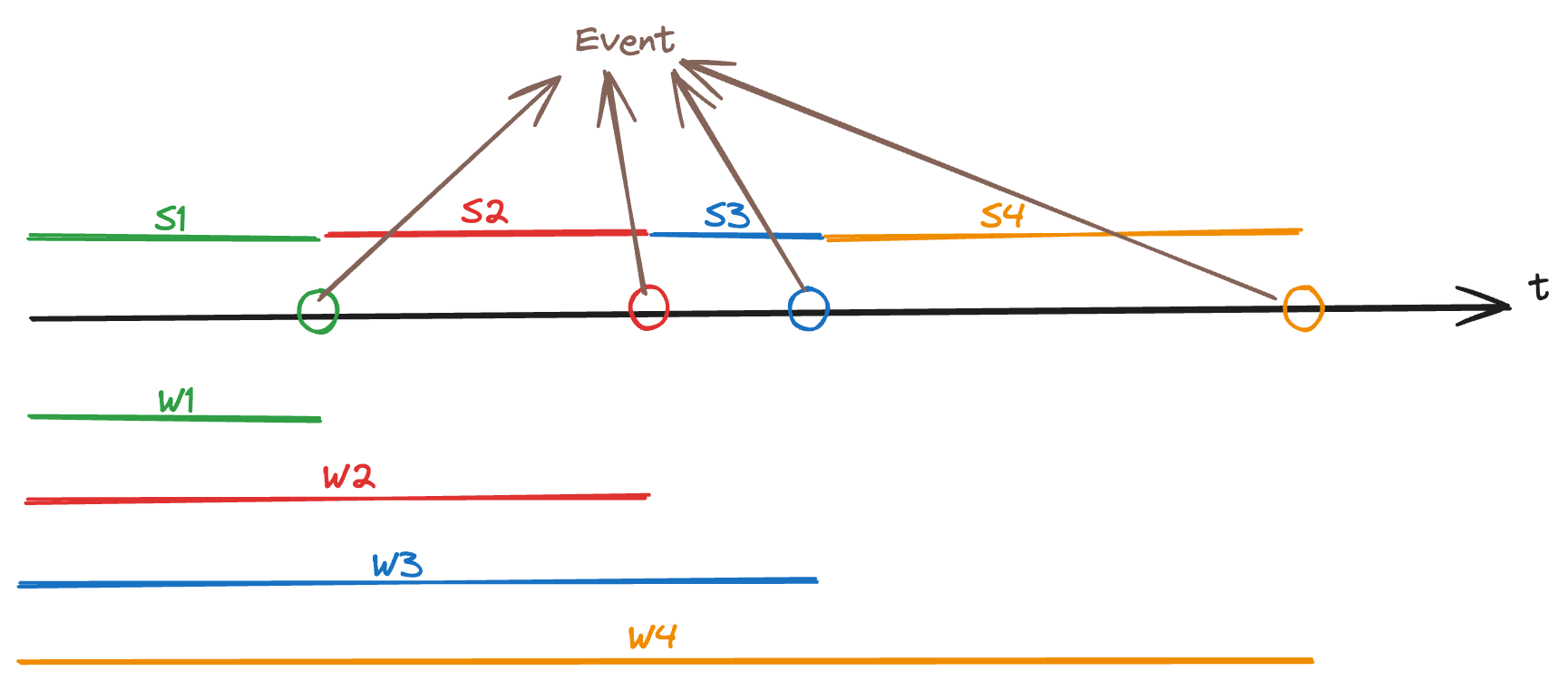
Then, basically knowing the sojourn times (or equivalently, the waiting times) is enough to completely specify the poisson process.
It turns out that the waiting times follow a gamma distribution, and the sojourn times follow an exponential distribution!
💡 Theorem: Waiting Time
The waiting time has the gamma distribution whose PDF is:
In particular, the time to the first event is exponentially distributed with PDF:
The last equation should already give a hint: if the first waiting time follows an exponential distribution, then what happens if we “restart” the process (by simply “shifting” the time unit) every time an event occurs? Then, of the original becomes of the new process and even this new process has the same probabilistic structure, so also follows (the same!) exponential distribution. Hence, also follows the same exponential distribution And so on.
We can keep “restarting” the process at every event occurrence, and it’s clear that all the ’s are also exponentially distributed with the same PDF (and they are independent, because we’re literally “restarting” the process all over). Hence, distribution.
Recall that . The mean of the exponential distribution is and the variance is .
It’s intuitive to interpret the mean: the average sojourn time (aka time between any two events) is equal to the reciprocal of the average number of events per unit time. Example: If we expect to see 10 cars every hour passing a location, then the average sojourn time will be 6 mins, i.e., we expect to see a car roughly every 6 mins (on average).
Before moving forward, let’s derive the PDF for the waiting time of (that we’ve already stated above).
Our goal is to find a PDF that gives us the probability density for every (recall that is continuous here)
Then, if the first event occurs exactly at time , then and , for any (specifically we can take the limit as ).
So, instead of considering the PDF directly, we can find instead, i.e., probability of the first event happening before time . The event is equivalent to (both cases mean that the first event has already happened before ) and hence, .
Since , we can find easily to be:
Hence, we have the cumulative denstiy function of
By definition, the PDF is the derivative of the cumulative density function. So,
and we get our desired result - the exponential distribution 🎉
We can do the same derivation for a general as well.
Remarks
- Relationshp between and :
- The CDF of is given by:
- and exponential random variables are memoryless. This is also why we can arbitrarily start the poisson process at any time. That is, we can start observing the process at any time, and always has the same distribution. This is NOT always intuitive:
- Suppose the frequency of buses at a bus stop follows a poisson distribution with an average of 3 buses every hour. You come to the bus stop at 10am and no bus arrives even until 10:20am. Your friend then comes to the bus stop at 10:20am. The waiting time for him is still going to be the same exponential distribution (with mean = 20 mins), and since you will have to wait the same amount of time as him (you both board the first bus that arrives), you will have waited 20 mins longer than him 😢 This is because in a poisson process, disjoint time intervals are independent! (however, this assumption is rarely true in practice - people would get mad at SBS and SMRT if this assumption were true 😲)
- Another example: if a lightbulb’s lifetime follows an exponential distribution and it has already been glowing fine for hours, what is the expected amount of time we expect it to continue for before it dies? Well, . Starting at (or in fact, any ), the average number of more hours we expect it to glow for is → giving a total of hours. Again, this kind of assumption is rarely true in practice with bulbs 😖
- Formally, if , then is called the memoryless property → the future of is independent of the past.
- In fact, the exponential RV is the only(!) continuous RV possessing the memoryless property. So, memorylessness property indicates (aka implies) the exponential distribution.
- It’s good to model lifetimes/waiting times until occurrence of some specific event.
- Sum of exponential RVs follows a gamma distribution, so follows a gamma distribution when .
Hence, the above theorem and properties gives us another way to define the poisson process using sojourn times, as follows:
Suppose we start with a sequence of independent and identically distributed RVs, each with mean . Define a counting process by saying that the th event occurs at time
then the resulting process will be a poisson process with rate .
Using this perspective, we can easily simulate a poisson process on the time interval as follows:
- Set , , and to be a vector initialized to .
- Repeat
- Generate
- Set
- If , then exit the algorithm
- Increment
- Set
- Return (the vector of waiting times)
contains the time that every event happens. To draw the Poisson process, start with and increase by each time .
Distributions Related to the Poisson Process
What can we infer if we know that is a Poisson process with parameter ?
- At any time, we know that the distribution ?
- and follows a Gamma distribution.
Now, if we put and together
- What if we have already observed , and we’re interested in ?
- What if we have already observed , and we’re interested in the joint disribution of ?
Conditional Distribution
Suppose we are told that exactly one event of a Poisson process has occurred by time , i.e., , and we’re asked to determine the distribution of the time at which the event occurred.
Intuitively, we know there is a “uniform” probability that the event occurred at any time in the interval because the interval has a constant rate . Let’s prove this intuition more rigorously.
Let be the PDf of .
Since we’re given that , obviously → the first event must have happened in the interval and cannot have been after .
It’s generally easier to solve problems of the kind “what happens in the future, given that you know what happened in the past” → use bayes theorem, if necessary, to convert problems to this form and then solve using conditional probability.
We can use (the mixed form of) Bayes theorem now, and only consider :
Now, we know that . Then, .
The term is equivalent to finding the probability that there are no events between and (which is the same as too! → using constant rate property to shift the time interval as necessary). And we know that . That is,
And notice that in the denominator, is possible if, and only if, the first event happened at for some and then no further events happened in . Applying the law of total probability (continuous form):
Using the actual distributions, we get:
Solving the above, we get:
Substituting everything we have so far into equation , we get:
for , which is a uniform distribution over the interval (as intuitively expected).
It means that given , this one occurrence could’ve happened at any time point on with equal probability (density).
If we consider the generalized case that , and we want to know the joint distribution of , then we can use the same approach as before (exercise for the reader).
The final result is:
where .
It is basically the joint distribution of independent random variables (with an ordering restriction). Why? Because for exactly, we can just generate uniform random variables (since each event is equally likely to happen at any time), without considering the ordering of the events yet. Once we have the realizations, we can order them in ascending order, and assign to them accordingly.
Each of the Uniform RVs has density so the joint density (without “reordering”) is . But there are permutations of these orderings, and we consider all of them to be equivalent because we only consider the events in sorted order. That is, permutations of the realizations of these uniform random variables all map to the same “event” because we will order all of them the say way.
Hence, under the constraint , we have the density at every point.
Notice that we can simply consider permutations instead of considering what happens when two uniform random variables have exactly the same value. Why? Because that’s “impossible” - 2 different continuous random variables cannot have the (exact) same value ever! (read a good explanation here 🎉)
Moreover, when our quantity of interest does not depend on the actual ordering, we can simply use the above result instead of the following one. Example: We’re interested in or → this clearly will not change if we reorder the variables. So, we can simply consider each to be a uniform random variable and solve it without relying on order statistics.
Waiting Times
Now, we consider the waiting time to the th event (in order!).
Note that the joint distribution is the same with independent uniform RV. Hence, the PDF of is the same with the one for the th order statistic (taking the th smallest value from the realizations of the RVs).
Given that , the arrival/waiting times have the same distribution as the order statistics corresponding to independent random variables uniformly distributed on the interval , which is
It’s important to remember that the waiting times are NOT independent of each other! Clearly, knowing one gives you information (an upper/lower bound) on the other.
However, if we’re not concerned about the order of waiting times, i.e., we’re interested in a quantity that remains unchanged no matter what the order of ’s are, and we’re given , then instead of considering the ’s, we can consider INDEPENDENT uniform random variables on and find the quantity of interest on these uniform random variables instead. Why does this matter? Because now they are independent! So, we can even find out their variance easily (since the covariance terms vanish). We cannot directly do this for the ’s.
Why is the above true? Because the quantity derived from the independent uniform random variables has the same distribution as that derived from ’s. Each individual is obviously not going to be identically distributed with because the ’s are ordered, but ’s are not.