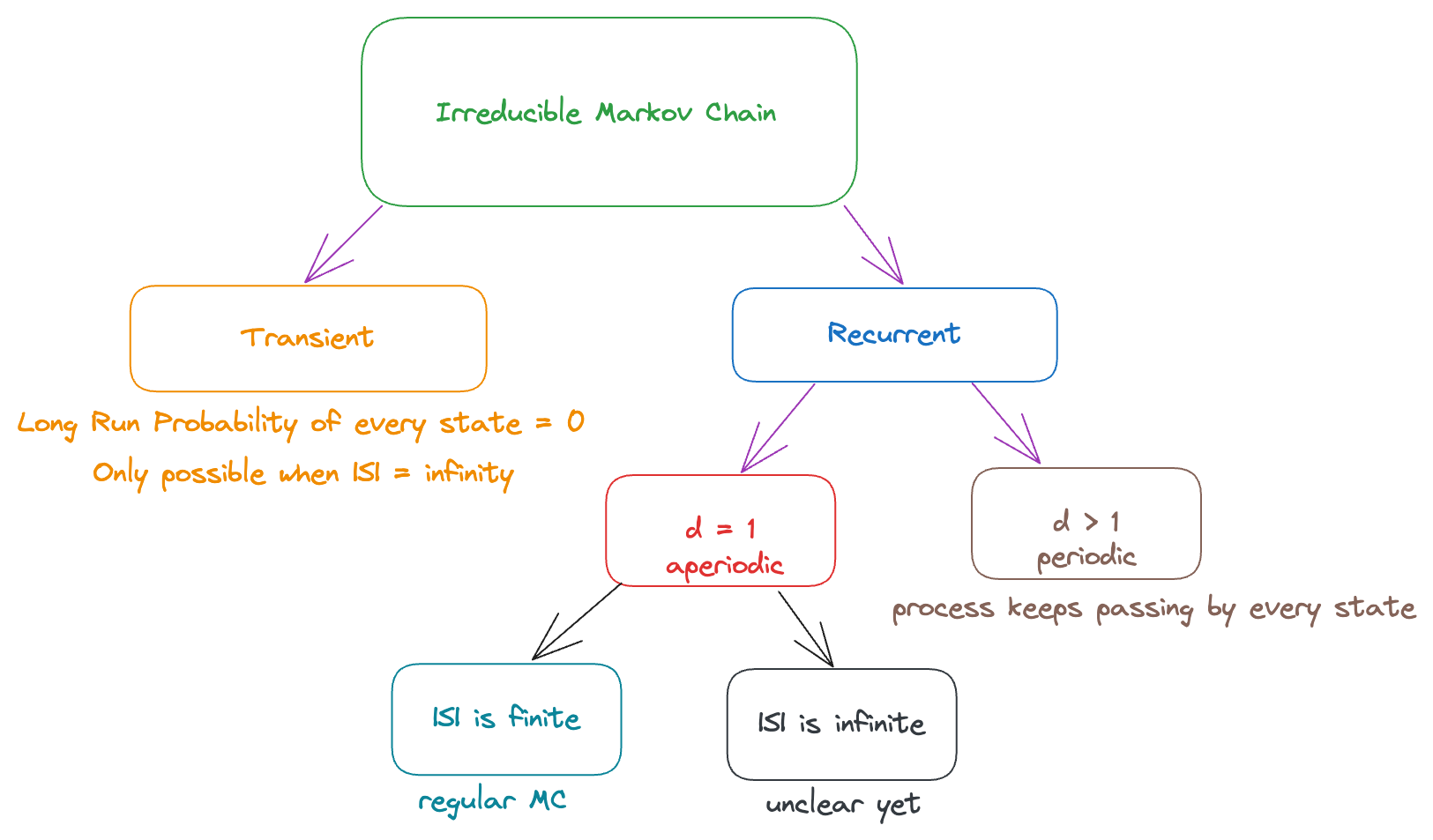
Long Run Performance
Introduction
Last week, we talked about the long-run performance of a reducible chain. The reducible chain can be decomposed into different classes. Then,
- in the long-run, the transient classes have probability 0
- in the long run, the probability of entering any recurrent class can be found by first-step analysis
Now, we’re interested to know the long-run performance of the states in the recurrent class itself. How will the process work? Is it possible to figure out the probability at each state?
Consider only one recurrent class. Restricted on this recurrent class, we can build a new MC (consisting of states only within this class). This new MC is irreducible (it has only one communication class). Hence, it suffices to discuss the long-run performance of an irreducible chain (because every recurrent class in the original MC consists of only one communication class, by definition, and so, the new MC will always be irreducible).
Reducible → We can “reduce” the size of the transition matrix by “reducing” the number of “states” (by clustering those in the same recurrent class together)
Irreducible → cannot be reduced further, i.e., like an “atom” of the MC
Period
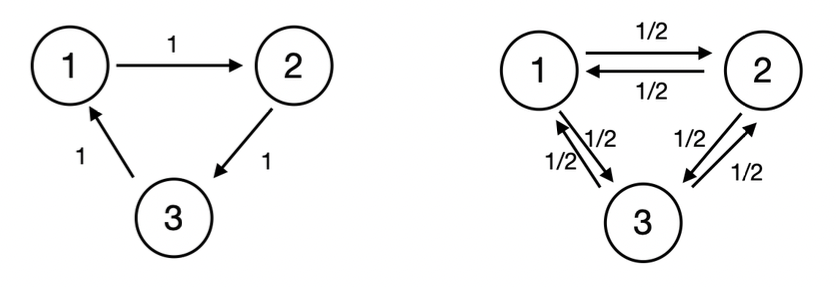
Both the above MCs are recurrent and irreducible. Also, the average number of revisits to any state is the same (infinity) in the long run. However, the pattern for both is very different and we should discuss them separately. (we want some way to quantify how the pattern is actually different).
Period: For a state , let be the greatest common divisor of . If is empty (starting from , the chain will never revisit ), then we define .
We call the period of state
Let’s try to understand this definition better:
- refers to the fact that the probability that is non-zero
- is the set of lengths of all possible paths that we can arrive at (starting from )
- Common divisor: taking the common factor of the length of these paths
In the figure above (on the left), only for Hence, the common divisor (and period) of state is . (Observe that all the states - - have the same period. Coincidence? 😲)
Another example is the gambler’s ruin problem. only for Hence, the common divisor is (it takes a “multiple of 2” steps to ever get back to the same state as the one we started from).
If , we call the state to be aperiodic.
Aperiodic intuitively means that there is no good pattern we can observe for when the process can visit a certain state.
Period of States in the same class
It’s natural (and quite intuitive) for the period of all states in the same class to be the same. Why?
Consider the previous example (above, on the left) Suppose that state 3 has a period of 2. Then, . Hence, for but that would mean that the greatest common divisor is (which contradicts the fact that the period is 2).
We can generalize this using a theorem.
Periodicity
For a MC, let be the period of state , then:
- If and can communicate, (read the proof here)
- There is an such that , and for any ,
- There is such that , and when is sufficiently large, we have
How can we interpret the above statements?
- The period of all the states in the same communication class is the same. So, we can think of “period” as being associated with a class (and not just a state, since it is common across all members of the class)
- Beyond a certain threshold (the “first” value of such that there is a path of length from ), we can always find a path of length from for any . Why is this true? Because of the definition of period, it must be “periodic” and the (minimum) duration between 2 revisits to is given by
- If I can go from in steps (and I know that the period of is , which means that there must be some threshold of for which there is path of length from ), I can go from ( steps) and then ( steps). Meaning, there is a path of length from .
Aperiodic MC
Note: Consider an irreducible MC (only one class all states have same period, ). Then, we can say that is the period of this MC. If , then all states are aperiodic, and we say that this MC is aperiodic.
Let’s apply the theorem on periodicity to an aperiodic MC, i.e., .
Consider the state . There must be some such that .
Then, by the theorem, we have that for any , .
But hmm.. how do we know that there even exists such an so that ? 🤔 This can be quite easily proven as follows:
- If the MC contains only one state , for all values of
- If the MC contains another state , then (because the chain is irreducible). So, there must be so that and . Therefore, we can set and there is a path of length with non-zero probability
Let denote the set of all states in the aperiodic irreducible MC. Then, for every state , there is such as for each state . When the number of states is finite, i.e., , we can define . Then, for any , we have:
In words, it means that for a finite aperiodic MC, there is a certain threshold (which is the maximum of all the individual thresholds ) such that beyond this, for any value of , there is path of length from for all states .
Consider two states and . Let be such that .
Recall that we have for . Hence, for any , we can go from ( steps) and then ( steps) and so,
Let . Then, for any , we have . (Beyond a certain threshold , we can always find a path of length from ).
But the above is only for a single pair of states - we can use the same argument on all pairs . For every pair , we have a . We can define (recall that ).
Then,
Let . Then, we have, for any .
In other words, all the entires of the transition matrix are non-zero. This can be interpreted to mean that after this value of , it is possible to travel from any state to any other state (including ) in a single step.
The above result is quite powerful (so much so that we define a new term for such an MC 😆).
Regular Markov Chain
A Markov Chain with transition probbaility matrix is called regular if there exists an integer such that all the elements are strictly positive (non-zero).
In such a case, we call to be the regular transition probability matrix. It means that for any . That is, using steps, we can walk from any state to any other steps.
Example: We know that thetra maximum degree of separation between any 2 people on Earth (under the “friendship” relation) is about 6. This means that in 6 hops, any person can reach any other person. So, if we model this entire graph using a transition probability matrix, will have all entries being strictly positive. (it’s not clear what the probabilities here would represent but this is just to give an intuition as to what “regular” mens)
Note: Obviously if all entires of are strictly positive, then for any , all entires of are also strictly positive.
Okay, so now we know that a “regular” MC is (in theory) but what’s an easy way to identify whether a given MC is regular or not.
If a Markov Chain is irreducible, aperiodic, with finite states, then it is a reguar MC.
Note that it only applies to MCs with finite states because in the derivation, we used the fact that is a finite number, but given infinite states, we can’t be certain what the maximum value of over all is (it’s possible for it to be infinity too, and so the derivation does not work).
🤔 Is the converse of the above statement true, i.e., are ALL regular MCs irreducible, aperiodic and have finite states?
Pro tip: If (there is a self-loop), (aperiodic instantly since the greatest common divisor of any set of numbers containing must be )
Lazy Chain: for all (the process is “lazy” and so, there’s a non-zero probability of it not moving away from at all)
Summary So Far
Regular Markov Chain
A regular MC must be irreducible. Why? Because by definition of “regular MC”, there is a number such that there is a path of length between any pair of states. So, all states communicate with each other. Hence, irreducible.
Q. Is the Gambler’s ruin problem with no upper limit stopping rule a regular MC?
Ans: No. Because the odd and even states alternate, the period of each state (and hence, the MC) is 2. E.g. if you start at , then (impossible to go from an even state to an odd state in an even number of steps ) and (impossible to go from an even state to an even state in an odd number of steps ). So, there is no value of for which all entries of the transition probability matrix are strictly positive (if is even, then all values (minimally) are zero, and if is odd, then all values are zero).
Limiting Distribution
Main Theorem
Suppose is a regular transition probability matrix with states . Then:
The limit exists. Meaning, as , the marginal probability of will converge to a finite value
The limit does not depend on (initial state). Hence, we can denote it by:
The distribution of all of the is a probability distribution, i.e., , and we call this to be the limiting distribution (it tells us how likely it is for the process to end up in any particular state in the long run).
The limits are the solution of the system of equations
Equivalently, in the matrix form, it is to solve:
The limiting distribution is unique (since it represents the long-term distribution of the process, there is only one right answer).
Recall that .
The second statement is true because under the limit , the initial state doesn’t matter (this is only true for an irreducible, aperiodic MC with finite states, i.e., regular MC) because all states can eventually reach other and we’re interested in the eventual distribution (called the limiting distribution) of the process.
Since each of the represents the probability of the process being at a state after a very long time, the sum of all the ’s must be 1 (since the states are “disjoint” and the process must be at any one of the states at any time).
Understanding this deeply is very important: in the long run, will converge to , no matter what the initial state is and no matter what is (even, or odd or whatever).
It should be evident that is a (probability) distribution on . Consider as the outcome space, and define the probability measure on in the way that and the additivity. Note that this probability measure satisfies the “probability distribution requirements” → each of the ’s are non-negative and they sum to because
Note:
- Also, should ring a bell 🔔 Recall from linear algebra that this means that is an eigervector of with eigenvalue = 1.
- also means that this limiting distribution is invariant → running the MC for 1 more iteration (i.e., one more step) doesn’t change the distribution at all (this is also why we can claim that the distribution converges). e.g. if then even after one more iteration, there is a 50% chance that the MC is at state 1. Intuition: if infinite iterations have converged to this value, what’s one more iteration going to change 🙄 (infinity + 1 is still is infinity and the distribution should remain the same)
Interpretations of
Okay, but how do we really interpret ? There are many different (and all correct) interpretations of (depending on what we’re considering).
is the (marginal) probability that the MC is in state for the long run. We say “marginal” because it is not conditioned on the original/initial state and also not conditioned on the time (exact value of ). It simply means that if we leave the MC alone for a long time, and then come back to observe it, there is a probability that the MC is in state when we observe it, regardless of how it was when we left, and regardless of the exact number of steps the MC took in the time we were gone.
An intuitive way to look at this is to see if there is any “difference” in times even in the long run. For example, for the simple random walk problem: If we start from an even state, the probability that the process is at an odd state is at even time points, and the probability that the process is at an even state is at odd time points (even in the long run). So, the long-run distribution depends on the time point we’re considering. Hence, it’s not a regular MC because there’s no “limiting distribution”.
Proof (of the above claim that is the marginal probability): the marginal probability can be calculated by the following formula (simply using law of total probability):
For a large enough , we have defined . Then,
Moreover, gives the limit of (simply based on our definitions and understanding). Since is the probability that the process ends up in state in the long run, we expect all the entries of the th column of (as ) to be equal to (why? because every entry () in represents precisely the probability of landing at state if we start at state , after steps).
We can write this as:
Every row is the same, as . Interpretation? The th row of is the distribution of given . If the distribution of converges to the same distribution regardless of , then every row must converge to .
can be seen as the long run proportion of time in every state. But what do we even mean by “long run proportion of time”. Let’s define it formally.
Define the indicator function of to be:
Clearly, it can be used to check whether the chain is at state or not at time . (And it is a random variable because is a random variable).
The (expected) fraction of visits at state is:
The above steps use the following properties:
- Linearity of Expectation: The expectations of the sum of random variables is equal to the sum of their respective expectations
- The expectation of an indicator function is equal to the probability that the indicator function evaluates to 1
- As , . So, as increases, the “effect” of the first few iterations of the markov chain (where it’s not really “long-run” yet) become less relevant (as there are many many more terms that dominate the effect of the first few terms), and the average tends to converge to .
In simple words, the above formula means that if we count the number of visits to state and divide it by the current time, then the proportion converges to (for larger values of “current time”).
Until time , the chain visits state around times.
The above statement is only “true” (i.e., a good approximation) for large values of , as the impact of the initial states fades away gradually. You cannot expect this to be true for values like because obvoiusly it is possible for the chain to be impacted heavily by the starting conditions in the beginning.
Okay, we’ve shown that the regular MC will converge to a limiting distribution. And we have also shown that this limiting distribution is unique and very meaningful to us. But… how do even find this limiting distribution?
There are 2 approaches we can use:
- Calculate and let . When all the rows are identical, then is a row of (we can use computers to compute this quite efficiently using eigenvector decomposition, i.e., decompose such that is a diagonal matrix and then and computing the power of a diagonal matrix is easy because we can just raise each diagonal entry to the respective power).
- Sovle the system of equations as mentioned in statement 4 of the main theorem.
Example: think of the limiting distribution as being similar to the distribution of coffee molecules in a cup of milk+water. Even if you add the coffee powder on the left/right side of the cup (or even if you stir it), eventually it “settles” into a distribution (generally, uniform) and stays at that distribution from that time onwards (invariant property → once the limiting distribution is reached, it never varies).
Irregular Markov Chain
Now that we know how to understand the long-run peformance for a regular MC, we’re curious to know what happens if the MC is not regular.
Note:
- We have equations in total, where equations come from and the 1 equation that ’s sum to 1.
- We have unknown parameters:
- The rank of is since all the rows sum up to 1 (since it needs to form a valid probability distribution, the sum of all the probabilities of outgoing edges/steps needs to be 1) → recall that rank is the number of linearly independent columns but in this case, if we know the first columns (worst case), we can find the last column by simply subtracting 1 from the partial sum of each row. Moreover, it’s possible that the rank of the matrix be even lower than (consider the extreme case where all values in the first column are 1, then everything else is forced to be 0, and so, there is only 1 linearly independent column).
We know (from linear algebra) that for such a linear system (where the “coefficient” matrix is non-invertible - because the rank is not equal to the number of rows), there can be no solution (inconsistent) or infinitely many solutions (consistent but dependent). BUT this does NOT mean that there can only be "no solution" or "infinitely many solutions" to our system of equations because we have an additional equation (i.e., additional constraint) that . So, even if the rank of is less than , we can still have a unique solution (because of the additional constraint). Moreover, it can be shown that any transition probability matrix has at least one stationary distribution (which is a solution to the system of equations). So, the "no solution" case is impossible for our system of equations.
In fact, the rank of will always be less than (for both regular and irregular markov chains) simply because every row must sum to 1 (to be able to form a valid probability distribution). Hence, we may have a unique solution only when the rank of is (because then we would get linearly independent equations from and 1 more from the constraint, forming a total of linearly independent equations and variables).
When the MC is not regular, it’s possible that and for all (which means that all the states are transient).
When the MC is not regular, it’s also possible that we can find a solution . How do we interpret this? it means that if the initial states have a distribution , then after any steps, the chain also has a distribution on the states. Hence, it is called the stationary distribution (since it does not move/change).
Note that periodic chains may have a stationary distribution.
Stationary Distribution
Consider a MC with state space and the transition probability matrix . A distribution on is called a stationary distribution, if it satisfies for all that:
Note that if the initial distribution of is not , we cannot claim any results.
It is possible for an irregular stochastic process to have a unique stationary distribution too! The uniqueness of a solution to the linear system of equations does not mean that it is the limiting distribution.
Any stochastic process has at least one stationary distribution in the sense that . The proof can be found here.
Though limiting distribution and stationary distribution are “similar” in some sense, they don’t refer to the same thing mathematically (or even conceptually):
| Limiting Distribution | Stationary Distribution | |
|---|---|---|
| Initial Distribution | Arbitrary | (important requirement!) |
| Next step | Unknown | |
| Calculation? | (OR) | |
| Uniqueness | Yes, if there are 2 limiting distributions and , they are identical | No, it’s possible to have 2 different stationary distributions, |
| Constraint on MC | MC must be regular | No assumption on the regularlity or periodicity of the MC |
We observe that the limiting distribution is one of the special cases of a stationary distribution, i.e., the limiting distribution must be a stationary distribution (because once we reach the limiting distribution, it is also invariant, i.e., stationary/unchanging).
For a regular MC, the stationary distribution is also a limiting distribution. Hence, in many textbooks about regular MCs, stationary distribution and limiting distribution are used interchangeably.
Example of a stationary distribution: Consider a gambler’s ruin problem. Then, if the initial state is or , then the distribution of the chain never changes. So, we have two (distinct) stationary distributions: and where the th entry of the tuple refers to (the probability of being at state in the stationary distribution). It’s not a coincidence that all the other states have probability 0 here → they are transient, and we know that for , i.e., the chain will eventually leave these states so it cannot be “stationary” if there’s some probability/flow stored at any of these transient states. Does this mean we only have 2 stationary distributions? Nope. We have infinitely many such distributions. Any linear combination (with the “right” coefficients) of these stationary distributions will also be a stationary distribution (by the fact that a linear combination of eigenvectors is also an eigenvector). In particular, the set of all stationary distributions for this example can be written as: where and . For example, is also a stationary distribution (conceptually, if you start off broke 50% of the time, you’ll remain broke forever (stationary) for those 50% of the time, and similarly if you start of at ).
A key observation is that the stationary distribution must have for all transient states (and so, even the initial distribution cannot have a non-zero probability of starting from any transient state).
Recall from linear algebra that a system of linear equations has either:
- No solution (inconsistent)
- One unique solution (consistent + linearly independent equations)
- Infinitely many solutions (consistent + dependent equations)
As a result, a MC always has zero, one or infinitely many stationary distributions. (In particular, it cannot have 2 or 3 or any distributions for a finite value of )
Note: A process with “short-term memory” that doesn’t directly look like a MC (since the next state might depend on the past few states, instead of just the preceeding state) can be easily converted to a MC by including all the “memory” into the state itself. For example, if the weather can be either sunny or cloudy , and suppose the weather today depends on the past 2 days, i.e., depends not only on but also on (and hence, not a MC), we can convert it to a MC by defining . Then, contains all the information needed for us to determine the value of (hence, we transform the “multiple-step” dependency into a “single-step” dependency by storing all the information needed to make the next step in the current state - which makes it a MC since the next step becomes conditionally independent of the past given the current state).