Classification of States
Recall that in the beginning, we described 4 types of problems/questions that we’re interested in solving:
- Short-term questions (e.g. distribution of for any fixed ) → can be solved using Chapman-Kolmogorov Equation
- Strategy-related questions (e.g. probability of being absorbed at a given absorption state, expected time to absorption, expected number of visits through a state, etc.) → solved using first step analysis
- Long-run performance (e.g. when , what can we claim about ?)
- Extensions
Now, we’re focusing on long-run performance questions.
Consider the gambler’s ruin example. We know that there are 2 absorption states: and (once we reach either of these states, we never leave, i.e., the process (effectively) stops and we’re done).
We’re interested in knowing whether always achieves or ? Or is there a probability that the gambler will continue playing for infinite time and never go broke or reach dollars? What about the case when there is only one absorbing state (i.e., “greedy” gambler scenario who does not set any quitting rule for himself)?
More generally, we see that there are 2 “kinds” of states for the gambler’s ruin problem:
- Absorbing states → once reached, never escape
- “Non-Absorption” states → the process just “passes through” such states and does not “stop” when it reaches it.
Can we find “similar” kinds of states for other problems (so that our results are more generalizeable).
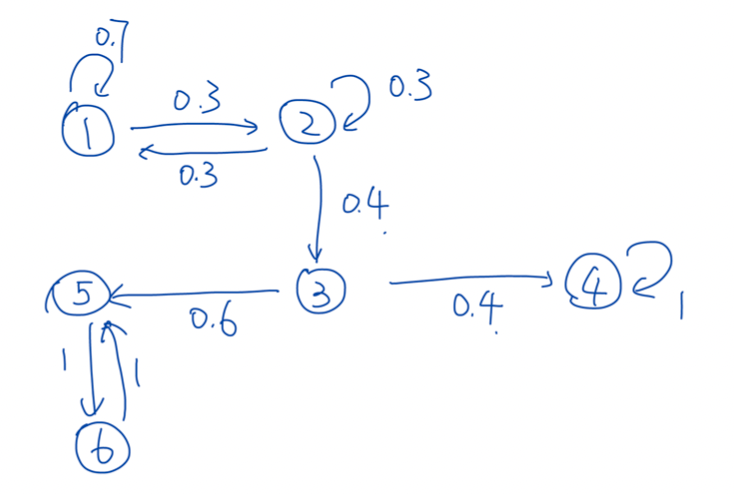
For example, in the stationary MC below, we see that states 5 and 6 are not absorbing states, but they form a “trap” for the walker (or the process)
Definitions
Accessibility
For a stationary MC with transition probability matrix , state is said to be accessible from state , denoted by , if for some .
The meaning is quite simple: if there is a path of finite length with non-zero probability from , then we say that is accessible from . When we say “path with non-zero probability” it means that all the edges along the path are “possible”.
Note that the requirement is not on the one-step transition probability, i.e., there does not have to be a “direct” edge (path of length ) from .
If , it means that there is at least one path of length with non-zero probability from . For example, if , there is at least one path with non-zero probability (here, denotes one transition).
Equivalently, this means that starting with , we can access at some finite step with non-zero probability.
Note: Unlike “distance”, the accessibility only considers one direction. That is, just because , it does not impy . An easy example is when we set and in the gambler’s ruin - since is an absorbing state, it can never reach . However, the gambler can reach from by simply losing the first round (which has non-zero probability ).
Communication
If two states and are accessible from each other, i.e., and , then they are said to communicate, denoted by .
“Communicate” basically means that both the states can “send information to each other”. In such a case, we regard and to be in the same “communication class”.
Imagine you put some “information” in state , then that information can “flow” to all states that are accessible from . Similarly, if there is “information” in 2 states and and they’re in the same communication class, this information can be exchanged between the states over time, i.e., they can communicate with each other.
From a computer science (or graph theory) perspective, we can say that the two nodes are “strongly connected”.
It is quite obvious that accessibility can be inherited - i.e., if and , then (there is definitely a path with non-zero probability from via - there might be other paths too, but at least there is this path).
Also, every state belongs to one and only one “communication class” (group of all the nodes that can communicate with each other): there is no overlapping, and no “leftover”. (think of this as the strongly connected components in graphs)
Communication classes form a partition of all the states → they are mutually disjoint and the union of all the classes must be the set of all possible states. (this is a direct consequence of the fact that the communication relationship is an equivalence relation, explained below).
So far it seems okay, but it’s still not clear why we care about communication classes. What’s the point of dividng the states by “communication”?
Communication is an equivalence relation, i.e.,
- Reflexive: ( for any , given that you’re at ,in steps, you are sure to remain at )
- Symmetric: (by definition)
- Transitivity: (by Chapman-Kolmogorov equation)
Any 2 states in a communication class can communicate with each other, i.e., ALL states of a communication class can communicate with (and ONLY with) ALL other states of the same communication class.
A typical “form” of a markov chain (without probabilities) looks something like this:
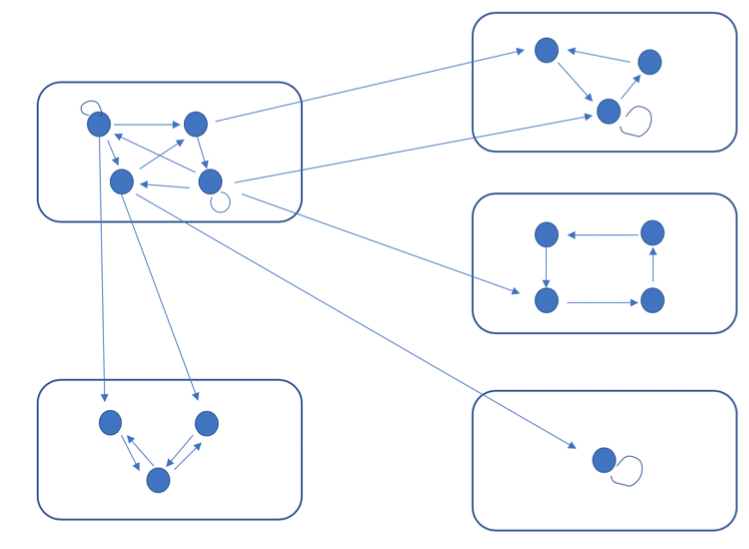
Here, each rectangle contains one class. No 2 classes cannot communicate with each other (otherwise they can be “merged” into a single class). And, we can see a “flow” between classes.
Intuitively, we can see that in the above diagram, all the “flow” will be pushed out (eventually) of the top-left class into all the other classes (because all the arrows point outward).
Let’s define another term now:
Reducible Chain: An MC is irreducible if ALL the states communicate with one another (i.e., there is a single communication class). Otherwise, the chain is said to be reducible (more than one communication class).
Why “reducible”? Because instead of focusing on each state, we can “reduce” the MC to its communication classes and deal with the “flow” between classes first, and then look into each class (separately). In particular, we can reduce the dimension of the transition probability matrix while we're performing FSA if we're only interested in finding out which classes the process enters. This is possible only because the communication classes (by defn.) are “isolated” from each other in some sense.
Note that an irrdeucible MC can have finite states, or infinitely many states. More generally, a communication class can have a finite or infinite number of states.
Recurrent and Transient States
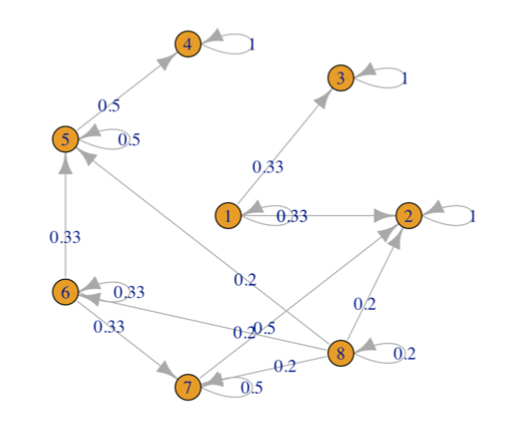
In the above example, we can (intuitively) make the following observations. In the long run,
- The flow will be trapped in states 4/3/2 finally
- If the flow starts from 1, then it will end in 2/3
- If the flow starts from 7, it may return to 7 for some turns but finally end in 2
- If the flow starts from 8, it may pass by 5/6/7 first but still end in 4/3/2 finally
In general, we see that the flow (or the process) will converge to some states (recurrent) finally. In the process, it may pass by some states (transient) but will leave them in the long run.
We want to describe this intuition more rigorously (and more quantitatively).
To do so, we need to define another term:
Return Probability: For any state , recall the probability that starting from state and returns at at the th transition is that:
According to the definition,
The return probabilty only captures the performance of , NOT related to the path: e.g. the walker can start from and stay there until the th step, or leave , passes by several times and comes back at th step, or leaves , visits other states and returns to at the th step.
The probability of ALL these paths of length whose final state (and initial state) is are summed up to .
If when , then the state is transient.
What this means is that “in the long run”, it is unlikely that the system ever returns to state .
We can calculate quite simply by raising the transition matrix to the th power (using Chapman-Kolmogorov equation). But the problem here is that we're more interested in finding out the distribution as and whether or not the process ever returns back to the state. For this purpose, is not very good because it cannot measure the probability that the process revisits in the long run (we can't just sum up all the 's under the limit because they're not disjoint events).
So, we can further narrow this to define a term “first return probability” → the probability that we return back to the state for the first time at .
First Return Probability: For any state , define the probability that starting from state , the first return to is at the th transition.
Note that we define (since it is difficult to claim what is the “first visit”, we simply set) (impossible to “return” to in 0 steps because we already start from )
Since it is the “first revisit”, (all the paths that contribute to for a given are unique to that → there is no overlapping, and so, the sum of all over is simply the sum of the probabilities of the union of a disjoint set of paths (basically a subset of ALL possible paths) and so it must be ).
Naturally, (since only includes a subset of the paths whose th state is whereas includes all such paths whose th state is ). Intuitively, imposes a stricter constraint on the path itself (so, the event for is a subset of the event for ) and so, the first return probability is of course, the return probability.
When does the equality hold? That is, when is ?
Intuitively, this means that in the long run, the process always comes back to at least once. We are guaranteed that there is at least one revisit to in the future.
Connection between and
What is the connection between and ?
Again, based on our (deep 😲) understanding of the terms themselves, we can “decompose” all the paths that contribute to into (disjoint) sets depending on when they “first” return back to . That is, every path whose th state is , can be broken down to (path from to first return back to ) + (remaining path). For example, if we’re interested in finding , i.e., the probability that we come back to state on step ( suppose that we have 3 states - 1, 2, 3 - none of them are absorbing, and we aren’t really interested in the actual probabilities but the paths that contribute to it instead):
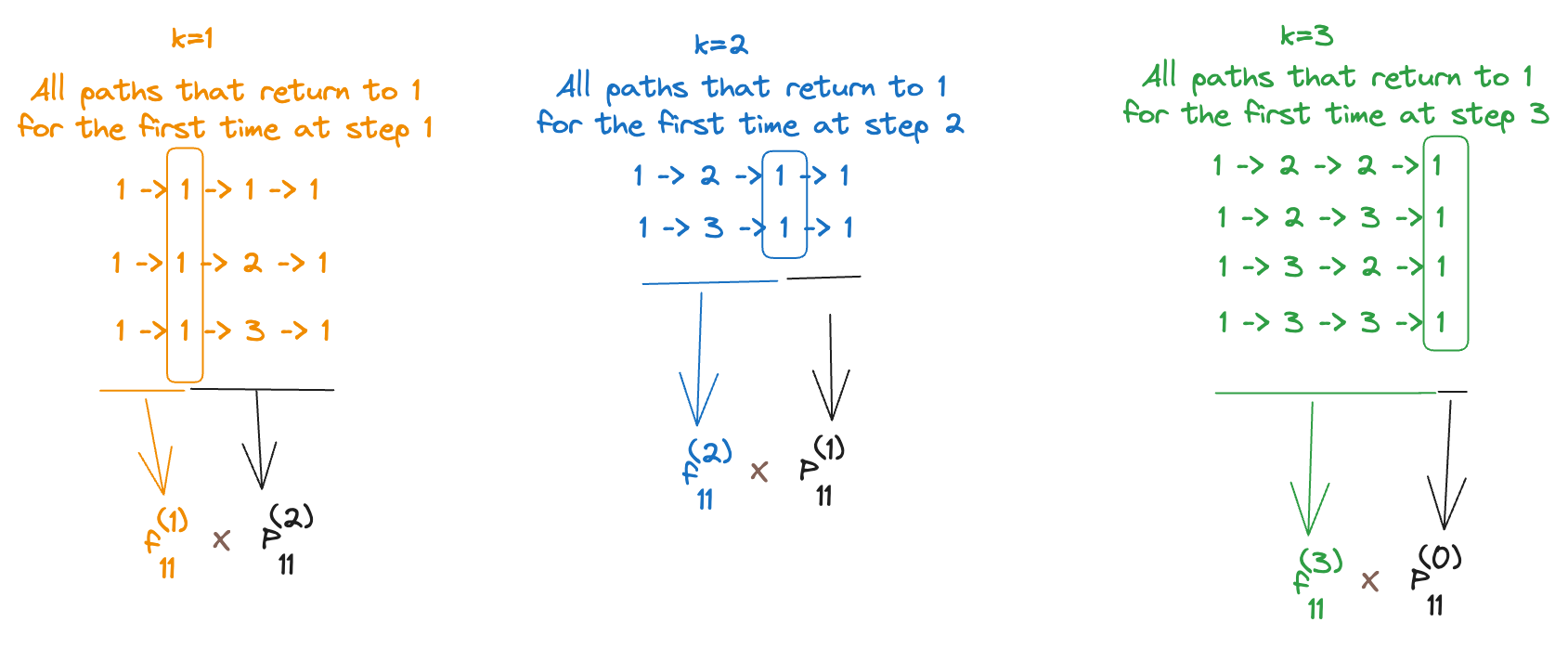
Let’s now “derive” this intuition mathematically. According to the law of total probability,
The last equality comes from (so adding an extra term doesn’t matter because it evaluates to anyway).
Theorem: Return Probability and First Return Probability
Remarks:
- Such type of formula is called a “convolution”
- We can find for all values of between and by raising the transiiton probability matrix to the respective power (using Chapman-Kolmogorov’s equation), i.e.,
Note: Recurrency .
For example, consider the following markov chain:
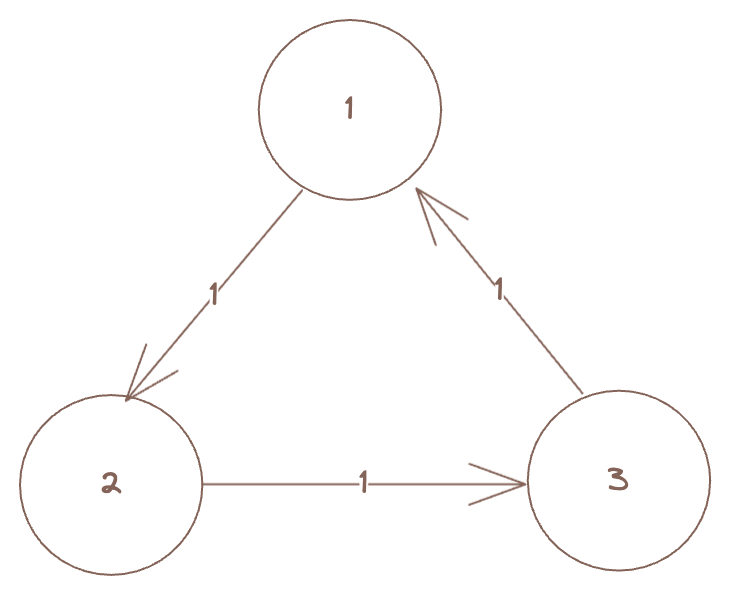
Then, all of are recurrent states.
In other words, there is no (convergent) “limit” as to what happens when and so, it’s not always possible to conclude that “recurrent” necessarily implies that as .
Let’s also define
In words, denotes the probability of revisiting in the future (we cannot directly use to denote such a thing because the ’s would not be disjoint, i.e., we would end up overcounting a lot of the paths).
Obviously, since it is a probability. (we’re making use of the fact that all of the ’s are disjoint events, i.e., for any , the event of is disjoint from → it cannot be that the “first visit” of state on the same path occurs at both and → by definition, we’re only concerned with the first visit. So, each path that contains state contributes to exactly 1 term depending on when state was first revisited).
With all this information in mind, we can (finally!) define what recurrent and transient states actually are.
A state is said to be recurrent if , and transient if
If we can guarantee that the process (or the “walker” 🤣) will revisit state (in finite steps!) for sure, then state is recurrent. Otherwise, the flow/process will eventually leave state .
In the MC shown above (with 3 states), all of are recurrent states since we can guarantee that in exactly 3 steps, the process will come back to the current state, i.e., for all and that is in fact, the only non-zero term in the summation. So, , and hence they’re all recurrent.
We can also think of recurrent states as those states which will contain the “flow” (process) in the long run.
To reiterate, recurrent state . The intuition is that the flow will come back on and on (again and again) and it seems to be trapped.
We cannot use as as being “recurrent” because of the counter-example we saw earlier (3 states forming a cycle with all probabilities of transition being ).
is the total probability of revisiting the state in the long run. as would be the probability of visiting the state at a time very very far into the future. They’re not the same. In fact, intuitively feels like an “absorbing” state (we are guaranteed that the process will be at state after a very long time - stable system). But recurrent absorption. An absorption state is always recurrent (since , the sum evaluates to ) but a recurrent state need not be an absorption state (consider the simplest case where we have with probability and the process flips-flops between the 2 states, never being absorbed but is still guaranteed to visit the current state in exactly 2 steps)
Number of Revisits
Intuitively, we “feel” that since we know that probabilistically, the system will always visit a recurrent state in a finite number of steps, as time goes to infinity, the recurrent state is visited an infinite number of times.
We can write it mathematically as such: Let be the number of times that the MC revisits state :
Then “recurrent” means (think what happens for an absorption state: once we visit an absorption state, we will always be trapped there, and so, we will count it infinite number of times (with each increment of (discretized time) )).
On the contrary, transient means that there may be revisits, but limited number of them, i.e., (i.e, it should be a finite number).
In conclusion, to show that this new definition of recurrent and transient is meaningful, we need to prove that it’s the same as the previous one. That is,
Theorem: Number of Revisits
For a state , consider the expected number of visits to , , then:
- If (i.e., is transient), there is
- If (i.e., is transient), there is
If we can prove the above theorem, we can conclude that both definitions of “recurrent”/”transient” (using and using ) are equivalent.
So, what are we waiting for? Let’s go ahead and prove this theorem.
Proof
means that when we start from state , there is at least one revisit. By our definition of , we can write it as:
Both the LHS and RHS are equivalent ways of saying “probability that we will revisit state at least once in the future”.
Now, consider the event → there are at least 2 revisits to state . Then, using law of total probability, we can write it as:
In general, we have: (we can easily show this by induction just as we’ve shown it for using )
In the third step of the derviation above, we “shifted” the MC by time units back since the probabilistic structure remains unchanged. In particular, the probability of visiting state twice given that you’ve already revisited it once is the same as the probability of revisting state one more time (having already revisited it once in the past doesn’t change the probability of revisiting it again in the future). So, we “reset” the counter (after visiting it at step ) and pretend as if we have to start over. It’s a neat trick to convert the to so that we can pull it out of the summation (since it does not depend on ) and then only calculate the ’s.
Now that we have the probabilities, we can calculate the expectation:
Here’s a simple illustration on how we “regroup” the terms in the expectation to fit the form that we need (it’s just a new way of thinking about the terms). Suppose we only had 3 values of - 1, 2, 3 - and we had to calculate . Then,
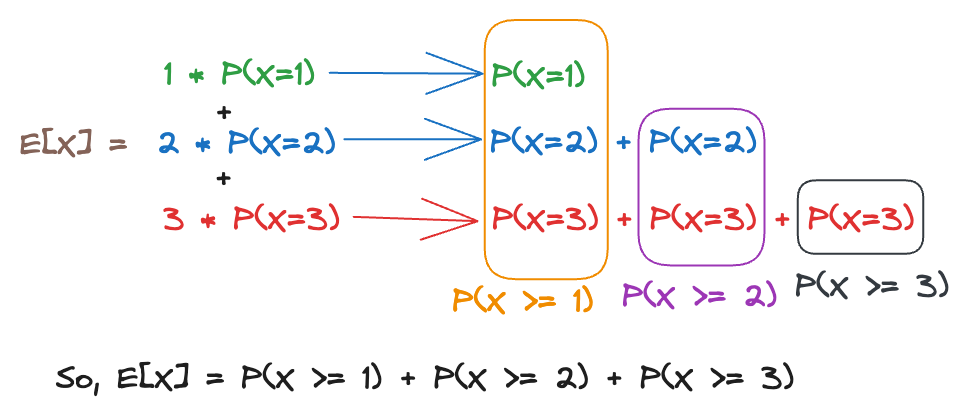
Okay, now we have: . But we already know that .
The last equality holds only when (because only under that assumption, we can apply the sum of geometric series formula here).
Consdider the recurrent case where . All the previous analysis holds except the last equality: so we have for all values of . (obviously, the series will not converge if all the terms are and we’re summing an infinite number of terms). Then,
Hence, we’ve proved both cases (transient + recurrent) of the theorem. 🪦
Remarks on the theorem:
- This theorem sets the theoretical evidence for the definition of recurrent/transient states.
- For transient states, the expected number of revisits increases when increases. However, eventually, we will leave never to return, i.e., we will never revisit again in the long run.
- For recurrent states, the expected number of revisits is infinite, which means that the process revisits it again and again (forever) in the long run (there is no possibility of never visiting it in the future)
Coming Full Circle
Recall that we had begun our discussion with . Now, we wonder where it fits in the picture and how it relates to our result. That is, we want to relate to our definitions of transient and recurrent states.
Consider the definition of . We can express → number of times we revisit state (and each time we visit , it is captured by the indicator function turning “on”).
Then,
From the previous theorem, we know that is finite for transient states and infinite for recurrent states. Then, we have:
- is finite for transient states
- is infinite for recurrent states
So, we can define recurrent and transient states using this definition too, as such:
State is recurrent if, and only if,
What does the above theorem really mean?
- For recurrent states, starting from any , we have , which means there is always a significant probability to return back to even after a very long time.
- For transient states, the revisitng probability when . This means that in the long run, the probability of coming back vanishes (and we can say that “all the flow eventually moves out of the state, never to return”).
Phew. To help recap, here’s a quick summary of everything we’ve discussed so far (all the equivalent ways of saying “transient” or “recurrent”):
States in the Same Class
Until now, we’ve discussed what transient and recurrent states are. But how does it relate to the notion of communication classes we had talked about at the beginning?
It turns out that there’s a pretty neat theorem for this.
If a state is recurrent and , then state is recurrent.
If a state is transient and , then state is transient.
Basically, it means that the recurrent/transient status can be seen as a status for one communication class (and not just one state in that class).
So, it makes sense to say that “a communication class is recurrent (or transient)”. This means that all the states in this class are recurrent (or transient).
Side Note: An MC with finite states must have at least one recurrent class. Why? Since there are only finitely many states, as time goes to infinity, at least one state would be visited infinite time (if all of them have being a finite value then the sum of all of them would be a finite value, but given infinite time, we cannot be visiting ALL finitely many states only finite times). Think, if all of them are transient where would the flow go after a very long time? It has to go to some state (which means that even in the long run, that state is still being revisited, i.e., it is recurrent)
Proof
Let’s prove claims (1) and (2) above.
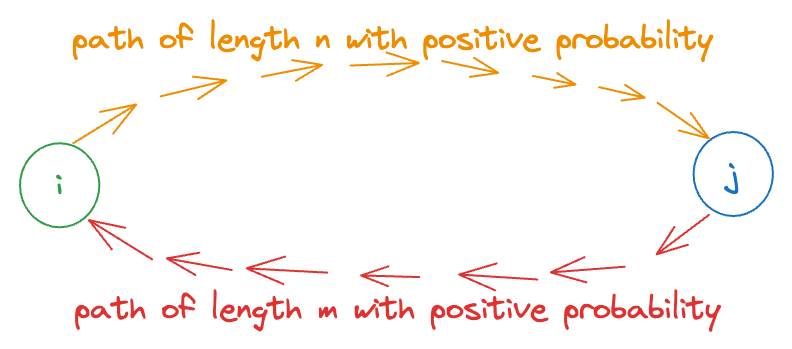
Since and can communicate, there must exist some integers and such that:
where denotes the -step transition probability from to . This can be visualized using the diagram below:
Consider any . Then,
The above equation (RHS) is basically saying that we can go from to (in steps), move around from to any other states until we return to in steps, and then finally, we take the path from to in steps. The LHS is “total probability of returning to in steps. Clearly, the RHS has a stricter constraint that the first steps and last steps lead to (and come from) state . So, the event described by the RHS is a subset of the RHS (i.e., the RHS has more such paths (e.g. even if we stay at for steps, that is a valid path for LHS, but NOT RHS). Hence, it’s an inequality (), not an equality.
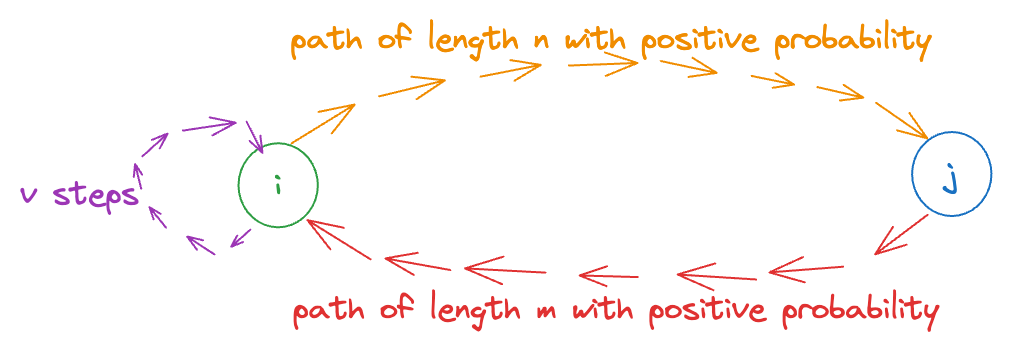
We can sum the above equation over on both sides (since it must hold for all ). Then,
Also,
since the RHS is a subset of LHS (and it’s possible for there to be other paths from to with length .
So, combining the 2 equations, we have:
When state is recurrent, (by definition). Then, since and are non-zero probabilities, we have: , which means that even is recurrent.
With a similar analysis, we can show that if is transient, then is transient too (and vice versa too).
Reducible Chains
For reducible chains, there are multiple classes:
- For a transient class, in the long run, the probability that the flow/process stays in this class (or ever returns back to this class after a very long time) is zero.
- For a recurrent class, when there are finite states, there must be a least one recurrent class (otherwise, where will the process go after a long time?). If is a recurrent class, then for any and (there are NO outgoing edges from a recurrent class. why? because which would mean that and so would be transient, contradicting our assumption that is recurrent). So, is kind of like an absorbing class (but within the class itself, the process can move from one state to another, without ever leaving this class).
We can figure out the probability of “entering” the recurrent class (using first-step analysis) and since the process cannot leave this class ever again, it makes our calculations simlper. Think of this as “collapsing” all the “similar” states into one “group’ and then dealing with the probability that the process moves from one group to another (instead of one state to another). For most cases, we’ll have much fewer communication classes than states so it makes our calculations in FSA easier.
Hence, given , we can find the probability that the process stays in each class.
Example
Let’s work through an example to understand this better.
Suppose, we’re interested in calculating the long-run performance of the following markov chain (note that we’ll have to consider multiple initial states)
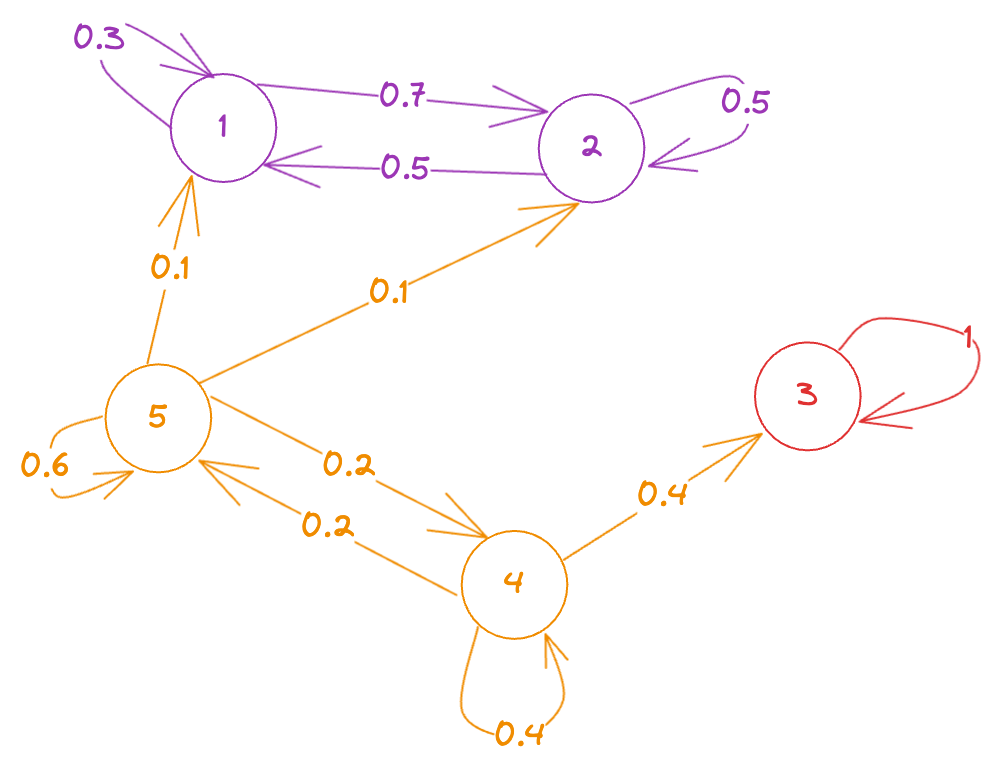
Clearly, we have the following communication classes:
- → recurrent class (no outgoing edges)
- → recurrent class (since )
- → transient class (since → this works because once we go from to , we can never return back to even with infinite time)
Obviously, if we start from a recurrent class, the process will never leave the class. And that’s not very interesting.
What we’re more interested in finding out is the probaility of being absorbed in class and the probability of being absorbed in class if we start from a transient state (either or ).
To solve this, we can create a “new” markov chain with the states in the same absorption class collapsed together to form a single “state”. We can’t collapse and together because they are the initial states we’re interested in (and the choice of initial state affects which recurrent class the process ends up in, in the long run) and so, they’re not “equivalent”.
Let’s call the class with states and to be class . Then, we know that (since there are only 2 absorbing classes in this example), probability of being absorbed in class = probability of being absorbed at state . That is, finding one is equivalent to finding the other too.
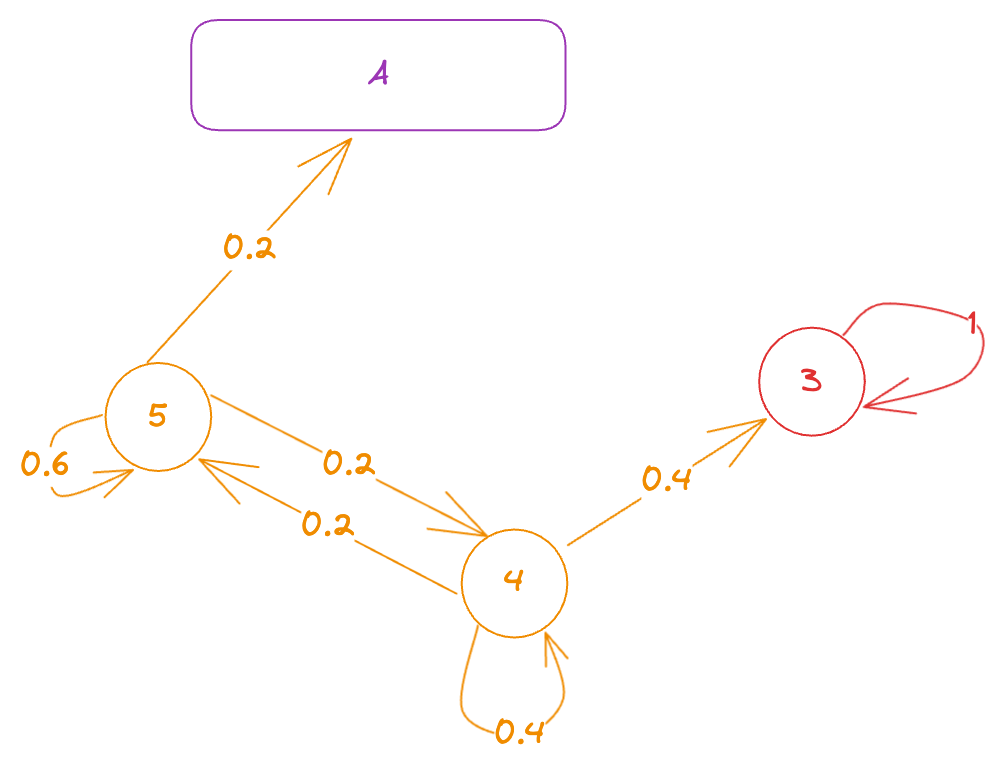
We’re only concerned with which class the process ends up going to (once it enters or , it cannot escape). So, we can treat the time when the process enters an absorbing class to be the stopping time (for now, we’re not concerned with what happens inside the absorbing class itself).
In other words, let be the stopping time.
Now, we can apply first step analysis on this “new markov chain”.
Let us define for . According to FSA, we have:
Solving it, we get: .
This means that if we start from state , there is a probability that we end up in class (and a probability that we end up in state ) in the long run, and similarly if we start from state .
Intuitively, this should make sense because if we’re at , we’re more likely to go to state than to state and the only way to reach class from state is through state . So, probability of being absorbed at state is greater than probbaility of being absorbed at class (and also higher than probability of going from itself 😲).
We can summarize all this as such: when , we have:
and,
Even when considering states in the same transient class as being the initial states, the long-run probabilities for entering the different absorbing classes will be different, so we cannot “merge” them (i.e., we cannot treat them to be the “same”). In other words, the probabilities for entering the different absorbing classes will be different depending on which transient state we start from, even if the initial states from the same communication (transient) class. Hence, the probability of entering the different absorption classes is a function of the initial state, NOT the initial class.
Gambler's Ruin with No Quitting
Imagine a greedy gambler who doesn't set any quitting time for himself, i.e., he only stops playing when he goes broke. Then, we're interested to know the expected number of games he plays before going broke (or does he play "forever" with non-zero probability?). (More formally, we're interested in the limit as )
Consider the symmetric case where .
Clearly, the communication classes are: and .
Since 0 is an absorbing state, it must have and it is recurrent (consider that there is a non-zero probability of getting absorbed starting from any finite state).
Now, consider . Clearly, (because once we go broke, we can never recover and hence, we can never revisit 1). This means that the communication class is transient. Hence, for all .
But does this mean that the gambler is certain to go broke? Can we argue that "since all other states are transient, they can only be visited a finite number of times (in expectation) and so, for a large enough , the process has to leave these transient states and eventually the gambler will go broke?"
The answer is no. Why? Although we have finite for all , we have an inifnite number of states. So, the time the process can spend in this "transient" class can be infinity (we're summing an infinite series where each term itself is finite). Intuitively, the process can stay at every state for a short time and it will still have enough (inifnitely many!) remaining states it can visit in the transient class.
Hence, although only has , it is possible that .
Furthermore, when , we have: (since the process "diverges" away from zero and wanders towards infinity in the long run). In other words, if the gambler is lucky (or is cheating), and he doesn't set any quitting rule for himself, then in the long run, we can expect him to have more and more money.
Note that when , the probabiilty of the gambler going broke (i.e., being ruined) is (you are guaranteed to go broke eventually). When , the probability of the gambler going broke is . A proof can be be found here.
Summary of Gambler's Ruin with No Quitting Rule
The following results hold for any finite initial state:
- If ,
- If ,
- If ,
In words, we can express the above results as such:
- If you're playing a fair game, you're guaranteed to go broke eventually (and in expectation you'll have to play forever to go broke). These two results may feel "contradictory" and "counter-intuitive" but are nevertheless both true.
- If you're playing a game where the odds are in your favor, you'll be playing an infinite number of games. Why? Because on average, you gain dollars on every bet. So, in the long-run, you're moving in the positive direction (away from the "broke" state, and towards "infinite money") and there's no absorbing state on that "end" (i.e., there is no end). Given infinite time, you'll be playing an infinite number of games (and you'll be making an infinite amount of money).
- If the odds are against you, the expected loss per bet is and so, in expectation, you'll go broke within a finite number of steps (you have a finite amount of money and you lose a finite amount of money on average per bet, then obviously you're moving towards "broke" state in every round). More precisely, if you start with dollars, you're expected to go broke in steps. And the probability of going broke is .
For a more rigorous treatment, you can refer to this.