First-Step Analysis
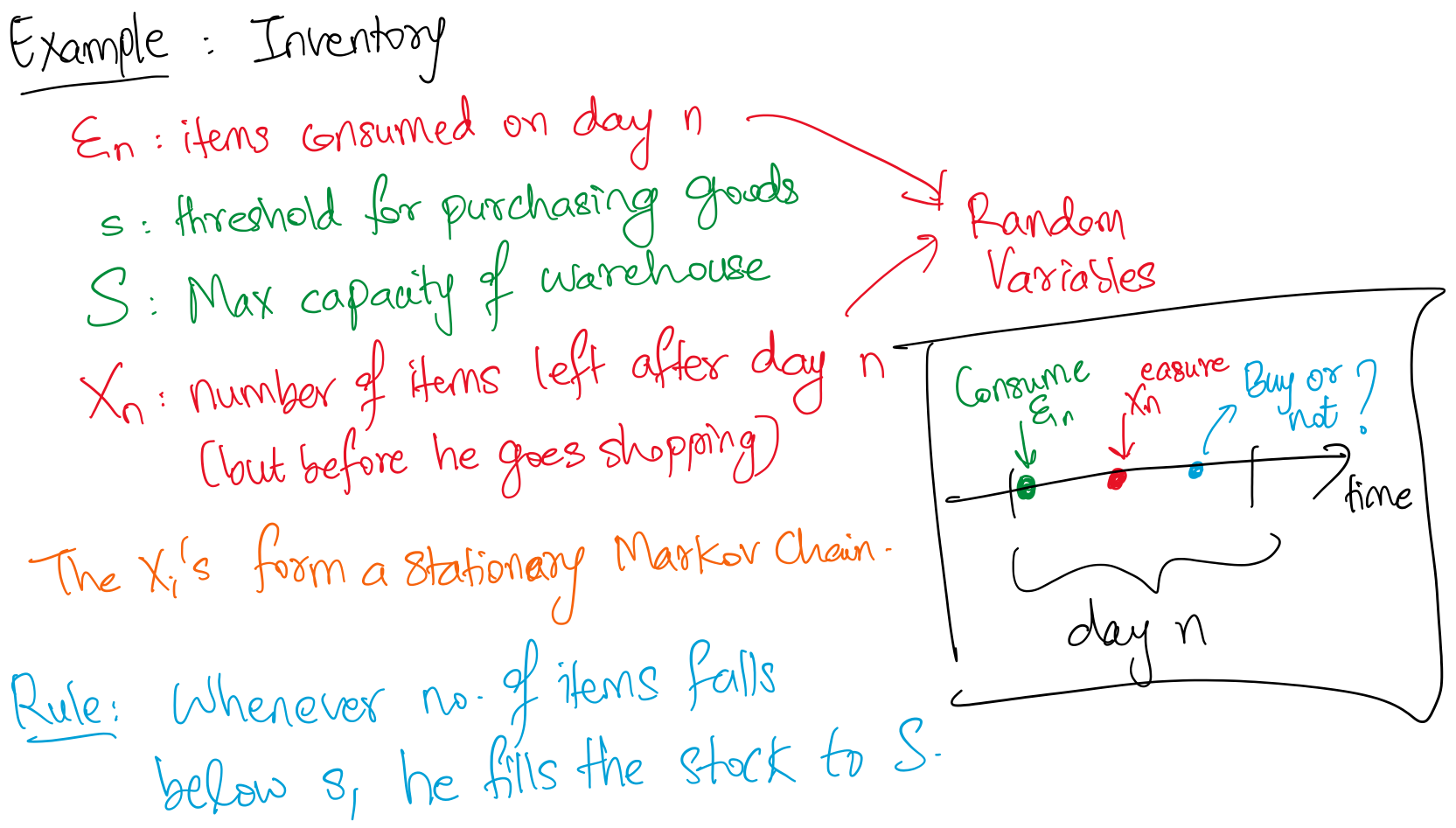
Example
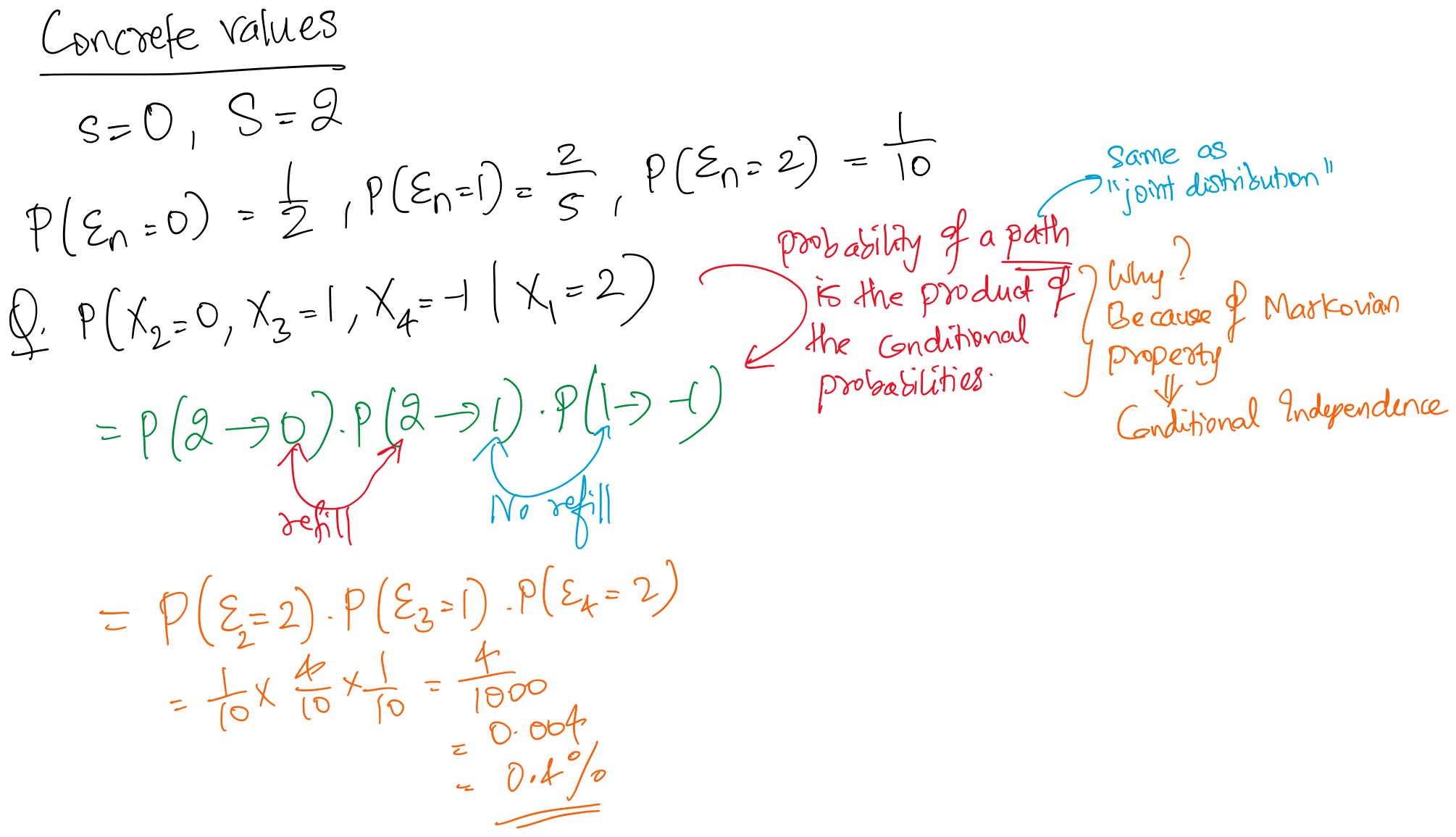
The above approach uses the law of total probability to find the distribution of (we just sum over all the values of and express the joint distribution as the product of the conditional distribution and the marginal distribution).
Alternatively, we can find the distriubtion of by finding the 2-step transition matrix which is equal to . In particular, we can look at the row of the 2-step transition matrix (since we’re starting from initial state ) and each value of row 2, column gives the probability of .
We generally use computers to calculate the matrix powers (and they’re surprisingly fast at this, since it can be parallelized).
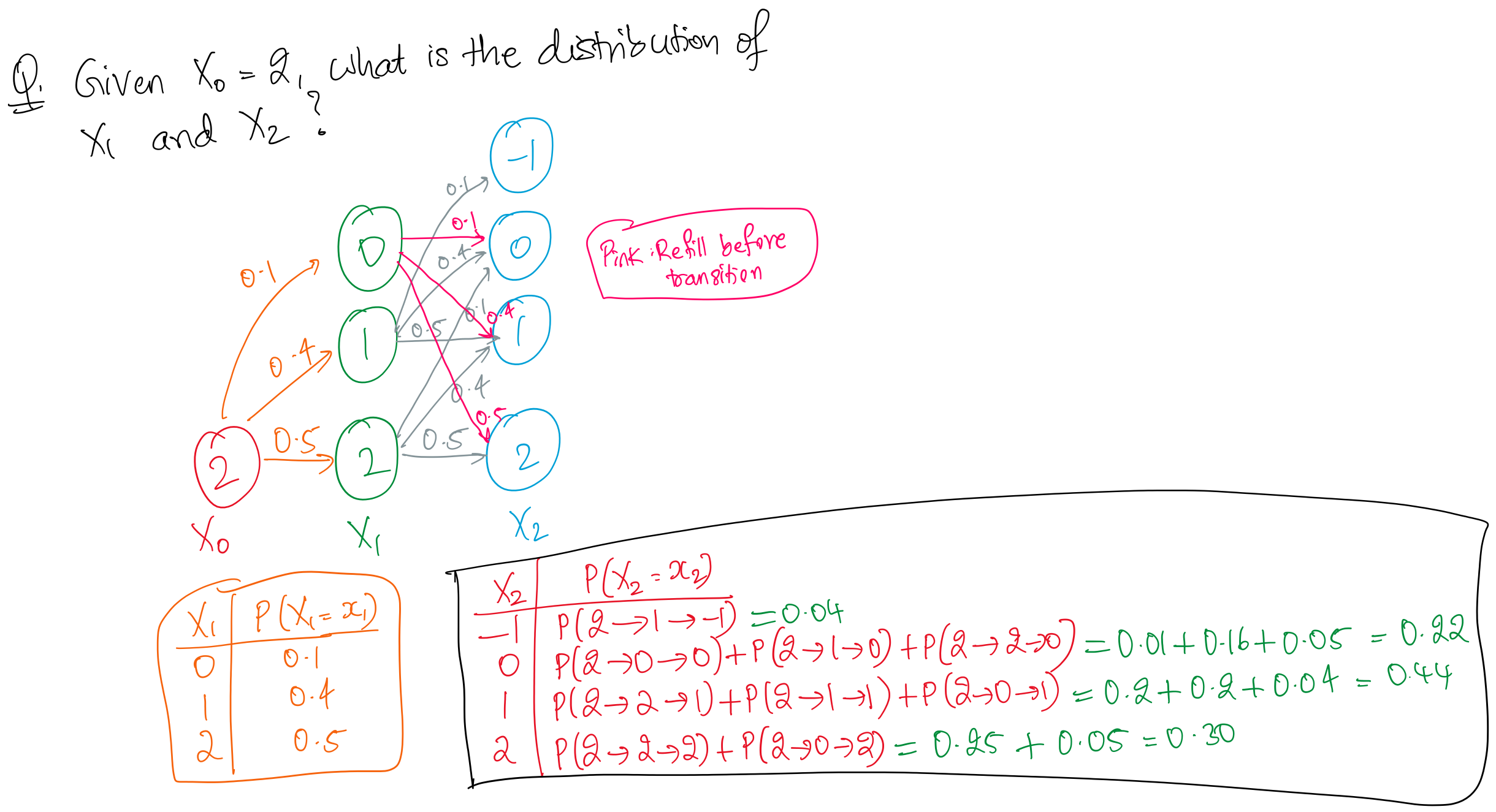
Now what if follows some distribution (i.e., initial state is itself a random variable) and we’re interested in the distribution of and ?
Recall that a distribution of a discrete RV is completely specified by assigning probabilities to a fixed set of values that the RV can assume.
We can decompose this as follows:
Note:
- is the one-step transition probability from to
- is the probability that
It’s super useful to be able to put the above equation (and steps) in words: from step (1) to step (2), we’re decomposing the joint probability into the product of the marginal distribution (of ) and the conditional distribution (of given )
Observe that the equation can be seen as the product of and (and then looking at the entry corresponding to ).
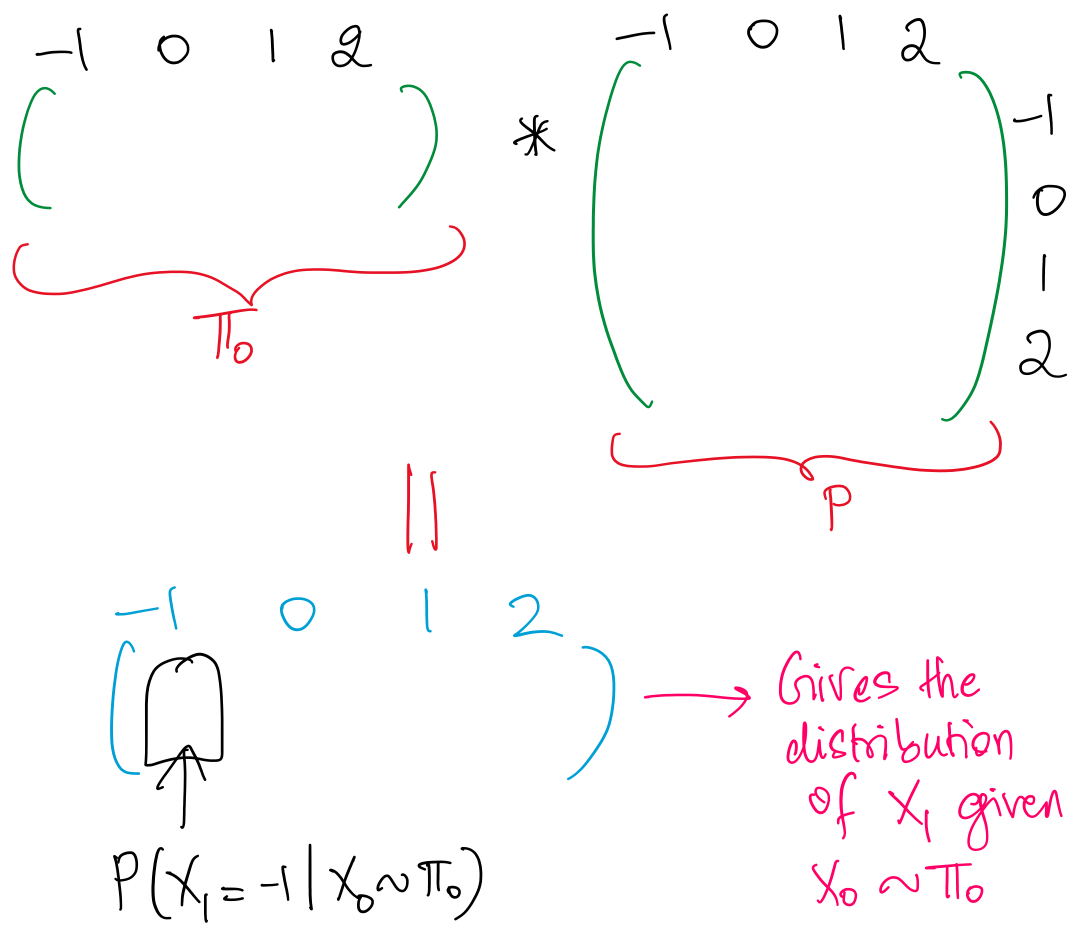
Looking at the product as a whole, we can see that it gives us the conditional probability of given that the initial state follows a distribution.
This also means that now follows some distribution, and we can repeat the procedure again. That is, suppose that , then gives the distribution of . But we already know (from above) that . Therefore, distribution.
In general, the distribution of given the initial distribution , can be expressed as
Even more generally, if we know the distribution of . Then the distribution for any can be written as .
Basically, we can multiply a distribution at time with a -step transition probability matrix, , to obtain a distribution for a later time . (very intuitive!)
Now that we know how to obtain the distribution of given the distribution at some previous time using 2 ways - law of total probability (by considering all possible paths) AND computing higher powers of the transition matrix - we can also find out:
- The expectation of
- In the long run, what is the expectation of ? Here, we can apply the limit and calculate the expectation of
Let’s come back to the Gambler’s Ruin problem and try to answer some of these short-term questions.
Suppose the gambler starts with dollars, has probability of winning each round , and quits when he reaches dollars or goes broke.
Then, we want to know:
- What is the probability the gambler eventually goes broke?
- What is the probability the gambler eventually wins dollars?
- On average, how many games can he play before he quits or goes broke?
We’ll soon see that the sum of the first two probabilities (to the questions above) is one, which means that there is ZERO probability for the gambler to oscillate FOREVER and keep playing. Why? Although there is some non-zero probability for this to happen for some fixed time period, when we assume “time tends to infinity”, this probability tends to zero.
Let denote the time that the gambler quits or goes broke. Then, we’re interested to find:
How do we solve this? Can’t we just find (-step transition matrix) and look at to find out the probability of going broke at time ? (i.e., can we use the same method we used to answer short-term questions with a fixed time here?)
No! We don’t know what is so how can we find ?? More formally, itself is a random variable (we don’t know when he will go broke, and so calculating is not possible)
Okay, so what else can we do?
Earlier, we answered questions where the initial state followed some distribution and we were interested in the state at time . Now, we have a fixed initial state and are interested in the distribution of (we can then try to use this to solve our main questions)
Since is itself a random variable, we can use law of total probability and condition on all possible values of , as follows:
Though the above equation is mathematically true, the second term of the product is unknown, how would we find ? No idea.
Okay, so we can’t answer strategy-related questions (like those above) with the techinques we’ve learnt so far.
By the strategy (i.e. the gambler’s own rule that he stops after he goes broke or wins ), there is some “stopping time” of the process. (For a general process, there may not be such an explicit “strategy”, but they may still have some kind of stopping time)
Let’s define some terms that will help us to answer these strategy-related questions:
Absorbing state: If a state satisfies for all , then it is called an absorbing state (i.e., once you reach state , you cannot ever “escape” from it, and )
For the gambler’s ruin problem, and are both absorbing states (based on our definition of the quitting rules).
Stopping time: Let then is a stopping time. What this means is simply the first time that we reach any absorption state (i.e., the time we get absorbed). For the gambler’s ruin, the quitting time is a stopping time, where we set
Now, we perform first-step analysis.
While we cannot tell the exact distribution of , we have some intuition:
- If the game is unfair in the way that the probability of winning a round , then the probability of getting broke should be bigger
- If the gambler has more money at the beginning, the probability of going broke is smaller
We have such intuition because we understand what happens in one-step.
We can try to analyze what happens in a single step: we start from . After one game, we can either reach or .
Recall that is the state at the stopping time. So, gives us the probability of going broke.
The second term on the RHS vanishes because because we stop as soon as we reach dollars, so we cannot go broke.
Now, we’re interested in evaluating the first term. In particular, we don’t know what should be.
Intuitively, it should be pretty obvious that the probability of going broke only depends on the current state (and not on the “time” at all). And, is basically the probability of going broke given that you have dollars at . This should be equal to the probability of going broke if you simply started off with dollars. Mathematically, . We will now prove this rigorously.
Proof that :
- Define the process , where (why? because we want to convert the condition on to a condition on )
- Then, we have:
- The specification parameters of is exactly the same with that of and so, if we define to be the stopping time for the -process, then (basically is just one step ahead of at every time, and so will also terminate/get absorbed one step earlier). Also, the probability of and must be the same → they’re the same process (just shifted one time-unit apart)!
- Then, we have:
- From step (2), we can rewrite the LHS of equation in step (4) to be: . Hence, proved.
Phew. Okay. Now what?
Now, we have:
Notice the only difference between this and the equation we wrote earlier is that we changed the condition to be on instead of .
All the unknown terms are in the form . So, for notation’s sake, we define .
The interpretation is just that gives us the probability of going broke from state (we really don’t care about the time at which we reach state , but in the definition, we use ).
So, we have:
We have one equation, and 3 unknowns ⇒ cannot solve this (yet).
But we can write the same equation for all values of (on the LHS).
We have a linear system with 5 equaitons and 5 unknown parameters, we can solve this quite easily (programmatically at least). After solving, we get:
Our required answer is:
Summary of FSA
Summary of what we did in first-step analysis:
- We use the property that and are “probabilistically” the same process (only differing in the times) and hence, the probabilities should be the same.
- The stopping time is only related to the probabilistic structure.
- We then set up a series of variables:
- According to the Markovian property, we consider the first-step from every possible state, and set up the equations.
- We can then solve the linear system for the result.
This method works when we have numerical values but it is tedious if the number of states is very large. What if we start with dollars? So, we want to be able to come up with a way to solve a general “difference equation” (discrete-form of differential equation)
Similarly, we’re also interested in finding the probability of being absorbed at state . We can use 2 approaches (and verify that both give the same answer):
- First-step Analysis: Similar to the previous question, we can set up , build the linear system and solve for
- Based on results already obtained: We already know that the probability of going broke when starting with is . We claim (prove in next lecture) that the Markov Chain will be absorbed with probability (for sure, as time goes to infinity, the probability of getting absorbed tends to ). Since the only absorbing states are , the probability of being absorbed at state (”winning” the game) is equal to
Okay. We’ve answered the first two questions: what is the probability that the gambler goes broke and what is the probability that the gambler wins 4 dollars and quits.
Expected Number of Games Played
We’re still left with the last question: what is the expected number of games the gambler plays before he goes quits? (Here, quits can be because he went broke or he got 4 dollars and quits)
In other words, we’re interested in finding: where stopping time of the Stationary Markov Chain.
Let
One key property that we’re going to use here is this: . In other words, we expect the gambler to play the same MORE rounds if he’s at a given state, regardless of the time at which he reached that state. But since he plays the same more rounds, the expected stopping time shifts by the difference in times at which he reached the same state.
The above equation simply uses the definition of expectation. In words, it means that the expected number of rounds the gambler plays before going broke can be found by considering all the possible rounds at which the gambler can go broke and multiplying each of them by their respective probabilities, and finally, summing them all up.
We can now perform first-step analysis, i.e., see what happens after 1 game.
Consider . According to the Markovian property, given , what happened afterwards is independent with . That is, given .
Therefore,
Now we need to relate with . This is quite intuitive: since we arrive at the same state at a later time, we don’t expect the distribution of to change in terms of the probabilities → we only expect each value of to be shifted by a certain amount, in this case 1.
That is,
Think of defining a new process . Then will stop 1 time unit before in all possible scenarios since “leads” . In the same way, the above equation simply means that if I expected the game to end at when you started off with dollars, I will expect the game to end at if you still have 3 dollars at . Why? Because I expect the game to follow the same trajectory as I had expected from to , only now I think of it from to
It might be easier to think of it as this: If is the expected number of games that the gambler plays from state before he quits, is independent of the time. It only depends on . So, if he has 3 dollars now and we expect him to play 4 more games before quitting, we should expect him to play 4 more games before quitting EVERY TIME he reaches a state where he has 3 dollars.
Here, is the stopping time of the overall process → NOT the “extra” time taken to reach absorption state from a given state (though it’s much easier to solve problems by using this method instead)
- The probability of getting absorbed at a particular state given you’re a state ONLY depends on the state and not the time. (we’ve already proved this)
- The expected remaining time before you get absorbed at state given you’re currently at state again only depends on the state and not the time (to be proved)
- As a consequence of (2), the expectation of the stopping time simply shifts by the amount of time passed since you last visited the state, i.e.,
Let’s prove this intuition rigorously now. The proof is very similar to what we did earlier to show that the probabilities of absoroption is independent of the time, and only dependent on the state.
We use the same process we created eariler that we defined to be , i.e., leads by one time unit. Then, obviously the stopping time of is
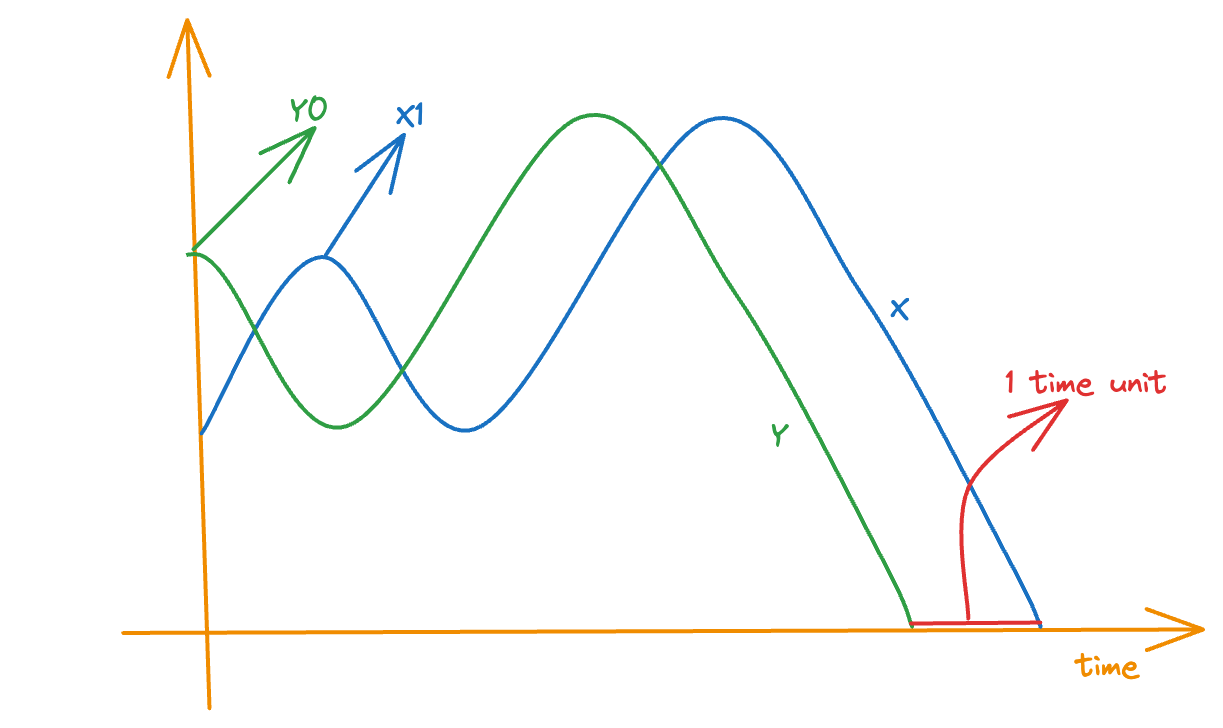
Then, we have:
The last equivalence is a result of the stochastic equivalence (i.e., same probabilistic structure) between and
As a conclusion, we have:
We can introduce this result into the original equation, nd we get:
We can do this for all and set up a linear system of equations, and solve for all values of .
(It’s nearly identical to the linear system consisting of ’s)
Observe the difference between the above equations, and the equations for finding the probability of going broke → it’s of the same form except for the extra “1” on the RHS → this is a result of counting every step that we take (since we're interested in the total number of games we played).
Notice that . In particular, it is not equal to . Handle the "edge cases" properly → the stopping time is defined as the the minimum time when we reach an absorbing state. So, if we start from an absorbing time, the stopping time is , NOT .
We’ve succesfully answered all the 3 questions that we were interested in! But..
This was only a special case of the more general gambler’s ruin problem (where the initial conditions can be anything, the stopping rule can be different, the probability of winning need not equal the probability of losing for each round).
Let’s try to generalise the results we’ve obtained. This is done in the next page.