Branching Process
Now that we’ve learnt everything, it’s time to apply it to examples! We’ll be looking at 3 main examples:
- Branching Process
- Ranking Pages in a Search Engine
- Monte Carlo Markov Chain (MCMC)
This page covers the first example, and the subsequent pages discuss the other examples.
Introduction
Branching process (aka birth-and-death process) is commonly used to model problems involving the population of a species.
As a motivating example, consider a population of monkeys in a group. Suppose we have only 1 monkey at the beginning (don’t worry about how the monkey will reproduce by itself 😆). At each generation, the monkey can give birth to monkeys and the old monkey will die.
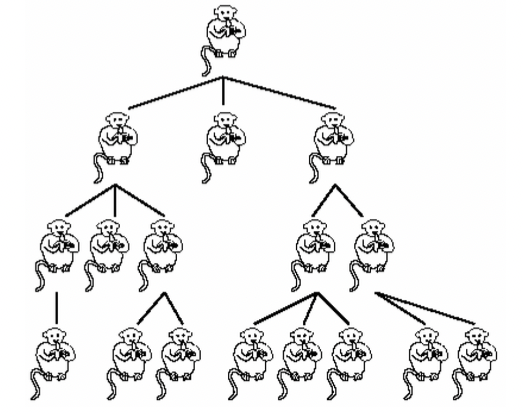
Clearly, is a random variable because every monkey can give birth to different number of children (generally called offsprings).
If we define to be the number of monkeys in the th generation, then the process is a branching process. (We call it a “branching” process because every edge in the population “tree” looks like a branch)
Here, we have: and monkey will generate new monkeys (and itself die), where are i.i.d. from a some distribution .
Hence, the th generation has monkeys. Observe that itself is a random variable that is independent of . So, this is a random sum!
Formally, we can define a branching process as such:
::: definition Branching Process
Suppose initially there are individuals. In the -th generation, the individuals independently give rise to number of offsprings , which are i.i.d. random variables with the same distribution as:
The total number of individuals produced for the -th generation is:
Then, the process is a branching process.
:::
Clearly, a branching process is a stochastic process. Moreover, it’s a stationary markov chain.
What parameters do we need to specify this markov chain? Well, if we know (initial state) and the distribution of , we can completely describe the MC.
Note: An important (and strong) assumption of the branching process is that is not dependent of . That is, the number of children an individual has does not depend on the current population. While this may sound reasonable in some cases, the assumption may not hold in other cases - be sure to verify this assumption before modelling a problem as a branching process!
Examples
Branching processes are not only useful for population-related problems. We can use them in other situations too. For example,
- Electron Multiplier: Each electron, as it strikes the first plate, generates a random number of new electrons, which in turn strike the next plate and produce more electrons, etc.
- Nuclear Fusion: Similar to electron multiplier, in every generation, some atoms combine together and produce enough energy to set of a chain reaction.
Motivating Questions
For every branching process, we’re interested in asking some questions (to predict the future, so we can plan accordingly):
- How many individuals will be alive in the -th generation? That is,
- Will the population ever go extinct? If so, what’s the expected time? That is, the minimum s.t.
Probabilistic Structure
Consider a simple case where . Then, the whole process looks like a tree (look at the picture of monkeys above).
If we have , then it’s identical to having independent trees (since all the are independent anyway) → just treat every monkey in the first generation as the root of a subtree. Alternatively, you can think of it as and that th generation created individuals (i.e., we can simply shift every generation by one to “force” the first generation to have only one individual and pre-assign certain values of for that first generation to “recreate” our given process)
Let be the number of indviduals of the th tree in the th generation. Then, .
So, we only need to analyze the case where and we can generalize the result quite easily.
Note: Actually in every (not just the first) generation, we can consider each monkey to be the “root” it’s own subtree and treat them as being independent of each other (and then, we can add them all up later to get the “total” tree).
What can we derive about the branching process?
To be able to derive anything, we need to have some information → specifically, we need to have information about the distribution of (which we denote by ).
We’ll consider 2 cases:
- Partial Information: We only know the mean and variance of , but not the exact distribution.
- Complete Information: We know the exact distribution, , of
Partial Information
Suppose we’re given that and . Further, suppose that
What can we derive about the process? Obviously since we don’t know the exact distribution of we cannot create a transition probability matrix. But does this mean we can’t do anything?
No! Since, we’re given the mean and variance of , we should be able to find the mean and variance of too!
Recall that for a random sum, we had obtained the following results (where and was a RV independent of the ’s):
So, applying those results to the branching process, we have:
Note that these results hold for all values of . So, we can use induction on to find the exact values of each of the and for all (since each term only depends on the previous term, and we’re given the initial “term” ).
For the expectation, we have:
So, the general formula can be written as: .
This should be quite intuitive because on average, every individual (in every generation) creates offsprings. So, the population growth is exponential.
Now, consider the variance. We can write it as:
The last equality holds because is zero (since it’s a constant number → no variance). Further, the geometric series “formula” only holds when (because if , we can simply add the terms to give ).
Hence, the general formula is:
The above results are for the initial state .
When we have , we know that and then the results can be adjusted to obtain:
The above result holds because of linearity of expectation.
The above result holds because the ’s are independent of each other, i.e., the covariance is zero → hence, the variance of the sum of independent random variables is equal to the sum of their respective variances.
Note: The variance of the sum of i.i.d. variables, is NOT equal to the variance of . Because if we’re only considering one term and multiplying it by , then, it is no longer independent → we will have additional covariance terms, i.e., and hence, we’ll end up with larger variance (by a factor of ). In particular, but if all the ’s are i.i.d.
Complete Information
Now, suppose we have the full knowledge about the distribution of , i.e., we know for all
Then, we can derive the transition probability matrix! (not explicitly anyway because may be infinite but we can calculate any entry if we want to)
We’re interested to find a (simple 😅) expression for (not just the mean and variance, but the actual distribution of ), and also the long-run performance of .
To do so, we need to define another term.
Probability Generating Function
::: definition Probability Generating Function (PGF)
For a discrete random variable , the probability generating function is defined as:
:::
Note that the Moment Generating Function (MGF) can be ued for both discrete as well as continuous RVs but the Probability Generating Function (PGF) is only for discrete RVs.
Similar to the MGF,
- is a function of ( is a pre-specified parameter whose distribution defines the function, it is not the input)
- There’s no randomness in . Evaluating the function at any value of gives us a plain constant number, not a random variable.
- is sufficient to completely characterize the random variable . In other words, there is a one-to-one mapping between and the distribution of .
In particular, once we have , then we can obtain the distribution of as such:The proof of the above is quite straightforward (by using induction on and taking higher order derivatives) and is left as an exercise for the reader 😮
- If and are independent, then → this will be quite useful for our branching process soon.
Distribution of
As we’ve seen that and are equivalent, we can derive the following quantities of interest instead:
- given
- given
Note that because we’re given the full distribution of , it is equivalent to knowing
Let’s try to find if we’re given
So, if we know (as a fixed number), we can find the distribution of , and therefore all the probabilities too.
Note: The above result is only useful when we know the numerical value (i.e., the realization) of the random variable (otherwise, we cannot raise to the power of if is a random variable).
We still need to express using the initial state. We can do this by considering as a distribution, and applying the law of iterated expectation:
As we’ve done several times already, we can use induction on (since the above result must hold for all ) and obtain an expression for that contains only the initial state.
Suppose our initial state is . Then, we have:
Note: → basically it is composing the function with itself times. That is, can be viewed as a function itself. In particular, → it has nothing to do with the power (although it’s unfortunate that the superscript notation we use for both might cause some confusion).
The final result (when ) is:
When , we can show that:
The above result is true because we just need to add the population in the trees, and since they’re independent, we can multiply their PGFs together. Recall that the PGF of the sum of independent RVs is equal to the product of their individual PGFs.
Extinction Probability
The branching process is a stationary MC with known transition probability function of , state space . Observe that the MC is aperiodic in the general case (unless there’s some weird constraints on - eg. only even number of offsprings are allowed)
Also, we can see that ther are 2 classes: and (Why? because is an absorbing state → once the population reaches , it’s not possible for a “new generation” to be created - a monkey 🐒 cannot just appear out of nowhere without any parent.)
Once , we say that the population has become extinct → it can never be revived.
So, naturally we are interested to know: what is the probability of the population going extinct? 🤔
And, if the population is “guaranteed” to go extinct, we want to know the mean generation at which it will become extinct (so we know how much time we have before we need to invent time travel ⌛).
Formally, we’re interested to find the long-run probability of the system entering .
Let be the extinction time.
Define be the probability of the population going extinct by the th generation, i.e., the probabiilty that the extinction happens in or before the th generation (and in either case, , hence the definition makes sense).
We’re also interested in:
is the total probability of extinction, i.e,. what is the probability that the population will eventually go extinct? If , then the population is guaranteed to go extinct in the long-run. If , then there is some hope that the population will continue indefinitely in the long-run and never go extinct.
Okay, now let’s start solving!
Suppose that (as before, we can generalize the results to later).
Recall that we have: . How do we find using this information?
Recal that . Also, will be for any finite value of , including . In particular, , not undefined!
Then,
If we evaluate the above expression at , we get exactly what we need, i.e., gives us the probability of the population going extinct by the th generation.
Also, since , we can say that
This also shows the power and versatility of probability generating functions - they can be used to express important quantities quite conveniently.
Now, we already have a way to calculate the extinction probability using PGF. But, for the sake of practice, let’s try to use First-Step Analysis (FSA) to derive the extinction probability in another way. Why? Because we should be able to! In all the previous MCs we’ve seen, we used FSA to solve problems related to the stopping time, and this should be no different.
Define be the probability of going extinct by the th generation if we start of with individuals. If we try to directly apply FSA to this, we’ll end up with too many equations, because both and are parameters here so we have to set up equations for for all and ! (in all our previous analyses of MCs, we only had a single parameter).
But there is a way to simplify this 😌
Recall that for a branching process, means that there are independent proceses with . Then, if is the stopping time of the original process (with ), and is the extinction time of the th branching sub-process, then the event . In other words, if we say that the entire population goes extinct, then all of the sub-processes (”branches”) must have gone extinct (and vice versa). If there’s even one it means that in the th generation, if we look at the overall original process, there is at least one individual alive in the th generation, hence the population cannot be said to be extinct.
Another way of looking at it is that and if we want (extinct), then each of the ’s must also be zero.
Therefore, by independence of the branching subprocesses,
where we define for convenience.
Then, we have:
The difference here is that can be treated as just a number → it’s no longer a “parameter”. We only need to set up the equations for for all
Observe that the above form is the same with the PGF of . In particular,
For sake of convenience, if we define , then we have:
Further, note that the only way the population (starting from one individual) goes extinct in the immediately next generation is when there are no offsprings of that individual:
So, we can calculate . Hence, we can also calculate all the other ’s. Hence, we can calculate all the ’s too.
If you’re wondering what is , naturally if you start with at least one individual. So, we can also write as .
And hence, → exactly what we derived earlier.
In summary, here’s the procedure for calculating the extinction probability by the th generation:
For a branching process, suppose the distribution of is given. The extinction probability is the probability that there are no more individuals at the th generation. It can be calculated as such:
Define the PGF of :
Set
Iterating for . So, now we have .
Calculate
Note that once we’ve found the extinction probabilities using the above procedure, we can also find the probability that the population goes extinct at exactly the th generation by , because . Obviously this also holds for when , i.e.,
Eventually Extinct
Recall that we have another question to answer: what is the probability that the population eventually dies out? That is, we want to calculate:
So, once we find , we can also find easily. Hence, the goal is to find .
First, we have to show that the limit exists.
According to the definition, ). Cleary, the sequence of ’s forms a non-decreasing sequence of numbers (because the event defined by is a subset of the event defined by ).
Moreover, since it is a probability. (this shows that there is an upper-bound on the numbers and so, the sequence cannot keep increasing without bound, and it also cannot ever decrease → intuitively, then it must be true that at after many terms, the ’s approach a constant value, i.e., they gradually “plateau” out and this value gives us the limit)
As a result, we can claim that the limit always exists.
Okay, so we know that the limit exists. But how do we find it? 🤔
There’s a really neat trick for solving such kind of limits. They make use of the intuitive property of a limit - that for large enough ’s, the value doesn’t change anymore. (We actually used a similar logic for the limiting distribution of a MC too)
In our case, we know that:
Under the limit, and noting that is continuous (by definition) so we have:
Note that we can only do the above because we can shift the limit inside, i.e, for a continuous function:
Hence, the value of must be the solution of the equation:
Let’s take a moment to analyze this equation.
Based on the definition, . When , and , we can calculate:
Further, we check the derivative:
which is always positive when . Hence, is an increasing function on .
The second derivative, as can be easily verified, is also positive on . Hence, will increase faster and faster.
We need to find the point of intersection of the function with the line (because we want the functional value of at the point to equal to the input to the function) in the range ).
There are a few possibilities:
- If , then and , so the extinction probability is zero. In other words, if the offspring is at least 1, then the population never dies out.
- If , we have 2 cases:
- Case 1:
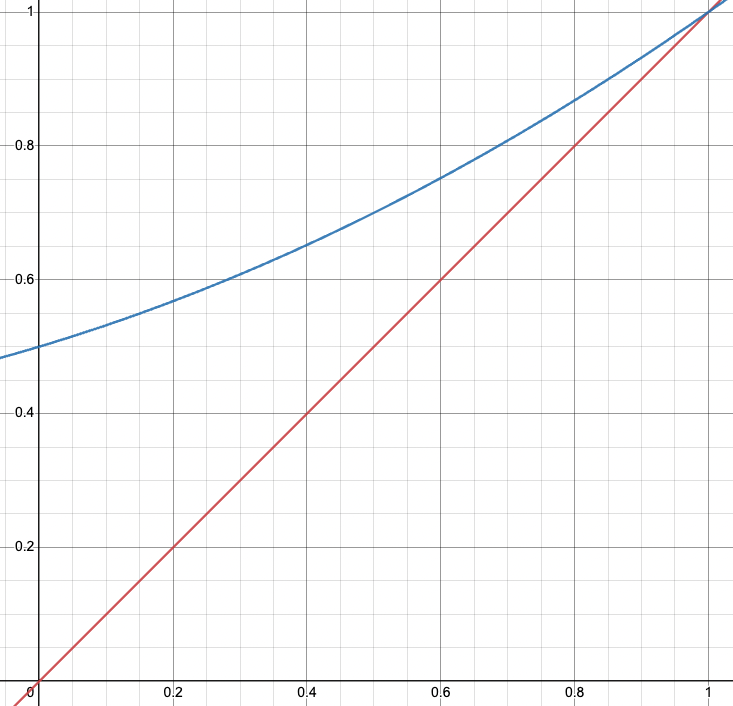 Blue line is and the red line is
Blue line is and the red line is - on and the only intersection is .
- Since exists and satisifes , so
- It means that in such a case, the extinction probability is 1
- Case 2:
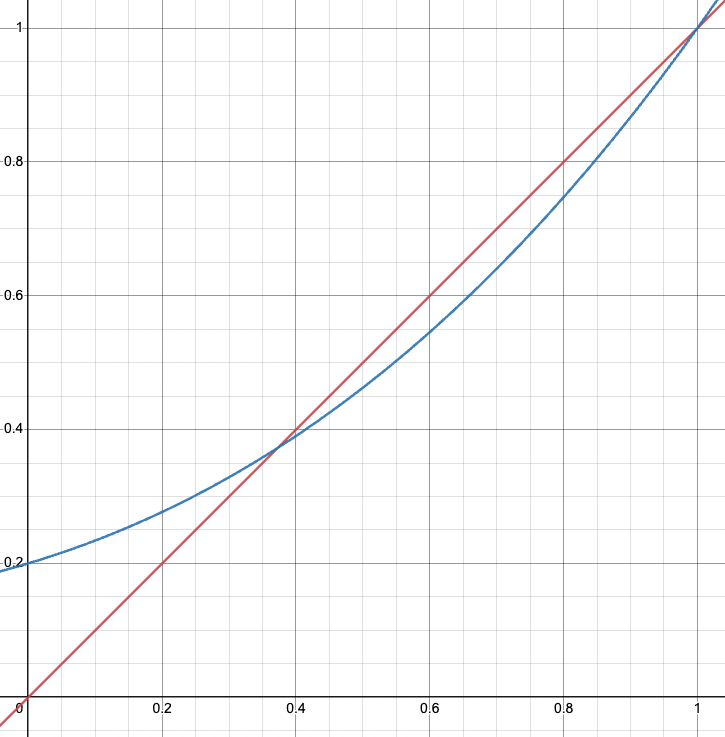 Blue line is and the red line is
Blue line is and the red line is - There is one and only one intersection of and on → and the second interaction is at
- is the -value of this intersection since it satisfies
- It means that in such a case, the extinction probability is
- Case 1:
But how do we differentiate the 2 possibilities analytically?
Note that the slope of the line is . In particular, the slope of the line is at the point as well.
Visually, we can see that:
- the curve with one intersection only has slope at , so that it can decrease to . This is because it comes from above, and needs to slow down so that the line can catch up with it.
- the one with two intersections has slope at , since it has to increase to . Here, it comes from below and so, it needs to increases faster than to be able to meet the line at
Hence, we can use to be the criteria:
- If , then there is only one interaction and
- If , then there are 2 interactions, and
Observe that:
Wow! 😮 Look how simple and intuitive this turned out to be!
The interpretation is really intuitive: if the birth rate (determined by ) per individual is more than , i.e., every individual, on average, produces more than one offspring, the population will not die. But if , the population has a higher death rate than birth rate because for every individual that dies from one generation to the next, he is producing, on average, less than new individual. This will eventually cause the population to go extinct. The case when is tricky → there’s a “chance” it may die out in the long-run.
In conclusion,
Consider a branching process with the distribution of as . The extinction probability can be found as follows:
- If , then → no chance of extinction because every individual generates at least one offspring.
- If and , then the process is called subcritical, and (the population eventually goes extinct)
- If and , then the process is called critical and (still goes extinct)
- If and , then the process is called supercritical and , and it can be found by the equation: where
The terms subcritical, critical, and supercritical are normally associated with nuclear reactions at nuclear power plants too. If the reaction is subcritical, it is “controlled”. If it’s critical, there’s a chance it can go on forever, but it will eventually die out too. If it is supercritical, it’s a big problem 💥