Markov Chain (Definition and Properties)
Let’s understand stochastic processes with the help of some examples.
Examples
Gambler’s Ruin
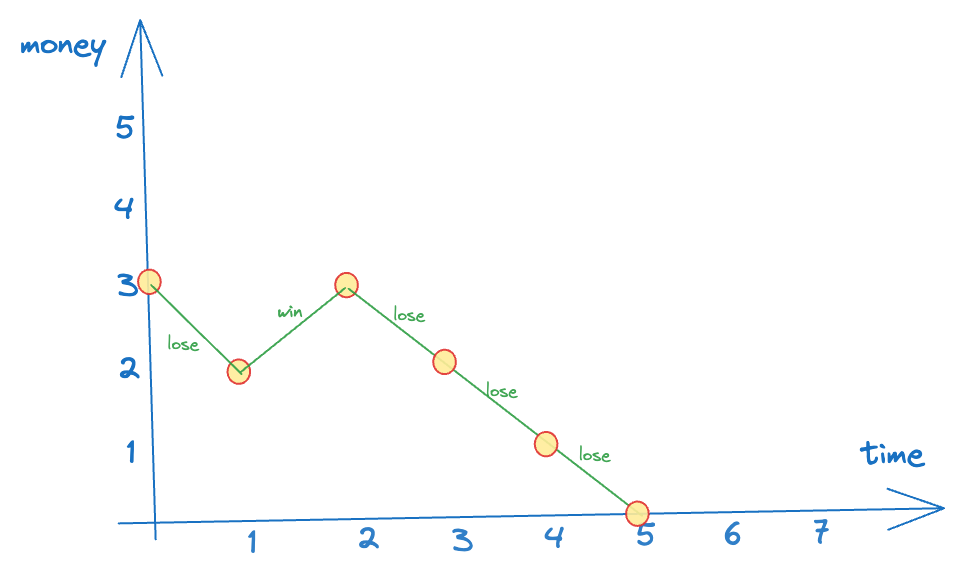
Suppose that Alice has and she wants to gambles. Every time, she bets . If she wins, she receives extra. If she loses, she loses the . She stops when she loses all dollars or achieves dollars.
Here, the time is “discrete” → we only care about the change in state when alice makes a gamble. Also, the amount of money Alice has at any time is also discrete (integral).
One possible outcome of Alice’s gambling can be as follows (say she starts with $3):
Poisson Process
The department of transportation is interested in the busy level of a specific location. They count the number of cars passing this location from time to time. This process is called a Poission process.
Here, the time is continuous, but the number of cars is a discrete (integral) value.
Stock Price
From time to time, the price changes, and the change can be any real number. It may not be an integer. Here, time is continuous and the stock price is also continuous.
Stochastic Processes
The processes in the above examples are similar but not identical:
- All processes have an index
- For every time point, the process has a value
- The range of and the possible values a process can have (at any time ) are different - they can be discrete or continuous.
Define the stochastic process as:
- Let be the index set. It can be time or space.
- Let be the state space, the set of possible values of the process.
A stochastic process is a collection of random variables where is the time index.
Classification of Stochastic Processes
Depending on the index set , we say the process is:
- A discrete-time stochastic process, if is countable
- A continuous-time stochastic process, if is a continuum.
Depending on the state set , we say the process is:
- A discrete-state stochastic process, if is countable. (more specifically, we call it a finite-state stochastic process when is finite)
- A real-state stochastic process, if is continuous.
Then,
- Gambler’s ruin → discrete-time, discrete-state
- Poisson process → continuous time, discrete-state
- Stock price → continuous-time, real-state
(In this module, we focus mostly on discrete-time, discrete-state processes - and so, the gambler’s ruin example is an important one)
Let’s come back to the gambler’s ruin problem.
Here are 10 possible paths for Alice without stopping, given and :
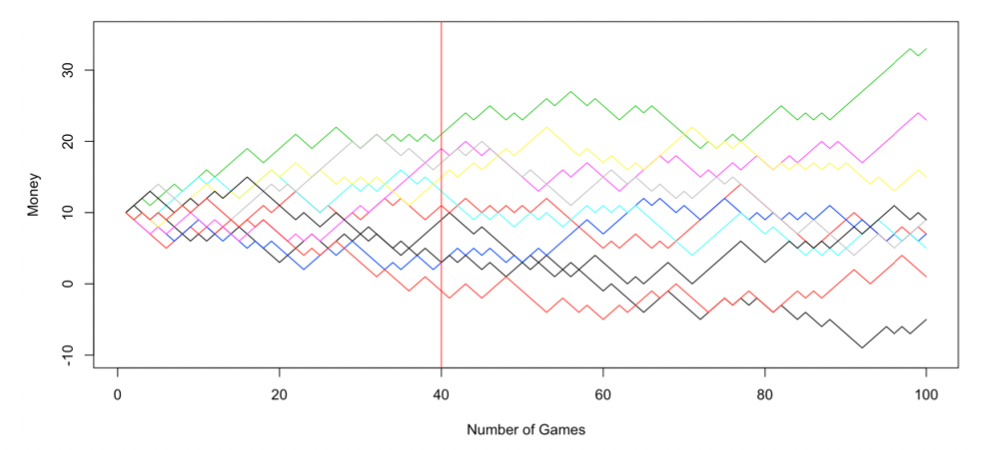
Each possible outcome is a path here. is the mapping from where we take the value of this path at (in the above graph, the value at the intersection with the red line)
The state space is usually constrained depending on which random variable we’re dealing with. If we’re looking at then is the same as the sample space of
Let denote the state (value) of the path at time . Hence, is a random variable.
is called the initial state
is the probability of any of the paths whose value at time is , i.e.,
Naturally, for , and can be independent/dependent (depending on the actual process).
How do we specify a stochastic process? We need to:
- Define and (easy)
- Give the probability of each possible path. But there are infinitely many paths, so for each individual path, the probability is zero (this doesn’t seem right! if the path has finitely many steps, the prob. is definitely non-zero → but even then, it’s not that easy to calculate). As an alternative, we identify the probability of each event, i.e., for any finite number of time points , we need the joint distribution of . Hence we need for any → but this is too difficult to specify if we consider such a general case.
But for the gambling example, the results of each game are independent so it’s much easier to write down the joint distributions.
Suppose that . Then:
In particular, the future of the path only depends on the current state, NOT the past history of the path. So, we can say that the future is conditionally independent of the past, given the present.
We hope that other processes also have this independence.
Markovian property: Given , what happens afterwards () is independent with what happened before ()
Mathematically, for any set of state and , we have:
Let be a stochastic process with discrete-state space and discrete-time set satisfying the Markovian property, then is called a Markov Chain (MC).
This should be quite intuitive → for a markov process, when trying to predict the future, we care about the latest known state (any of the given states) and we can safely ignore everything in the past.
As a concrete example, at time say that Alice has money then:
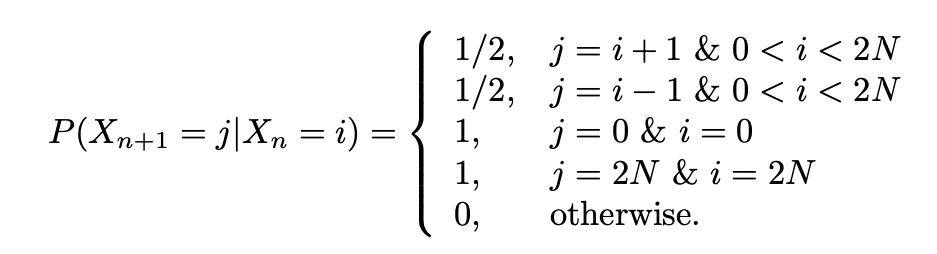
Our goal now is to find for any .
We begin with the simplest case: . Hence, we can rewrite our goal as .
It is a function of and we need the specification for it.
One-Step Transition Probability:
Now we consider the general case: . Hence, we can rewrite our goal as .
Given , it can be calculated:
Basically we want to consider all possible paths that take us from to and sum all their probabilities.
When computing this using an algorithm, we can use dynamic programming to optimize this. Here, the state is defined by (time, value). So, we can define dp[time][value] to be the probability of reaching the goal (n+m,j) (goal state) from (time,value). Obviously, many paths overlap → overlapping subproblems are where DP is useful.
Specification of Markov Chain
Recall that for a general process, to completely describe it, we need:
- Index set
- State space
- Joint distribution of
But for a Markov Chain, instead of knowing the full joint distribution, we can simplify it to be the one-step transition probability function (using which we can completely reconstruct the joint distribution): for ALL and .
Also, for a discrete-case, we can express the combinations of all possible transitions from time to in the form of a matrix, called the one-step transition probability matrix.
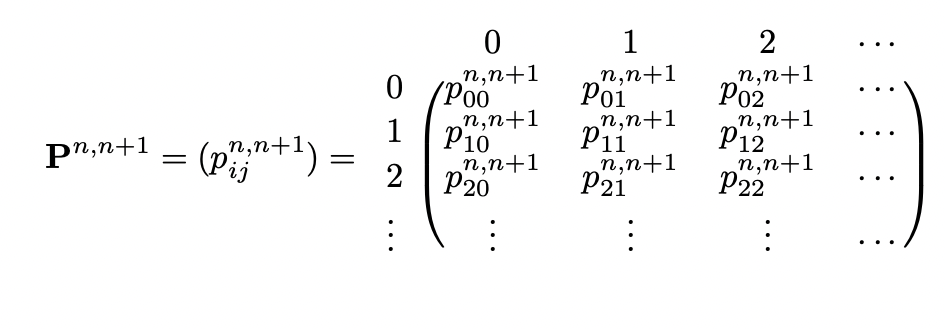
Bolded characters refer to matrices. But markdown cannot bold math symbols :(
In the above matrix, the -th entry of is equal to
💡 Think of a neural network with the weights on edges being the probability joining 2 nodes. (it’s also similar to a bayesian network in some sense):
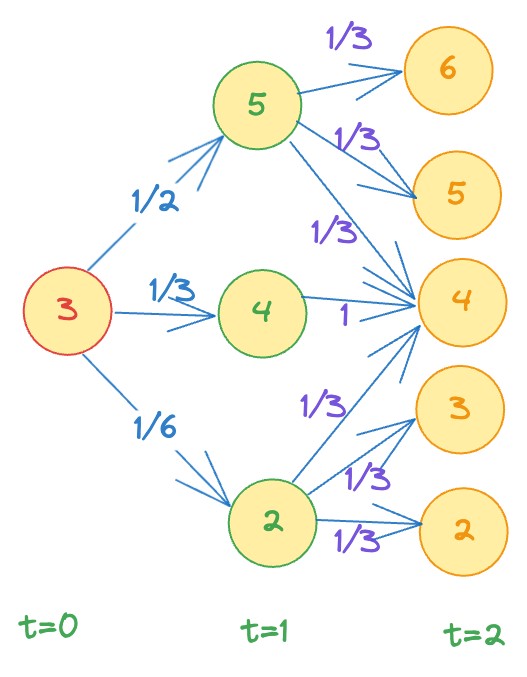
So, for example, the probability of reaching state 6 at time = 2 given initial state = 3 is just the probability of the path , and the probability of the path is just the product of the individual probabilities on the edges (by construction → weight of an edge joining node to node , from layer to layer is given by )
Another example: the probability of reaching state = 4 at time = 2 is the sum of all the incoming paths to the node 4. (this is where dynamic programming can come useful to speed up the computation).
Properties of a Transition Matrix
Every entry is a probability, and so, must be non-negative.
Fixed row sum: the sum of entries of any row is always because each row (say ) gives the distribution of and since it is a probability distribution, the sum must be 1.
Note: this does NOT hold for columns.
-step transition functions (Chapman-Kolmogorov Equations):
Any transition from time to must have gone through time so we can “split” all paths into 2 parts → time to , and time to . Then, the prob. of going from any value at time to any value at time is equal to the sum of prob. of all paths that go from value at time to value at time to value at time , FOR ALL values of . (again, it helps to picture a neural-network structure to visualize the different paths, and the fact that any path going through must have gone through for some value of (since time moves in one direction and to reach , it must have passed ).
In fact, in general:
thinkWhat does the Chapman-Kolmoorov equation really actually mean? It’s really intuitive → it basically says that you can multiply transition matrixes to get higher-step transition matrices. As an example,
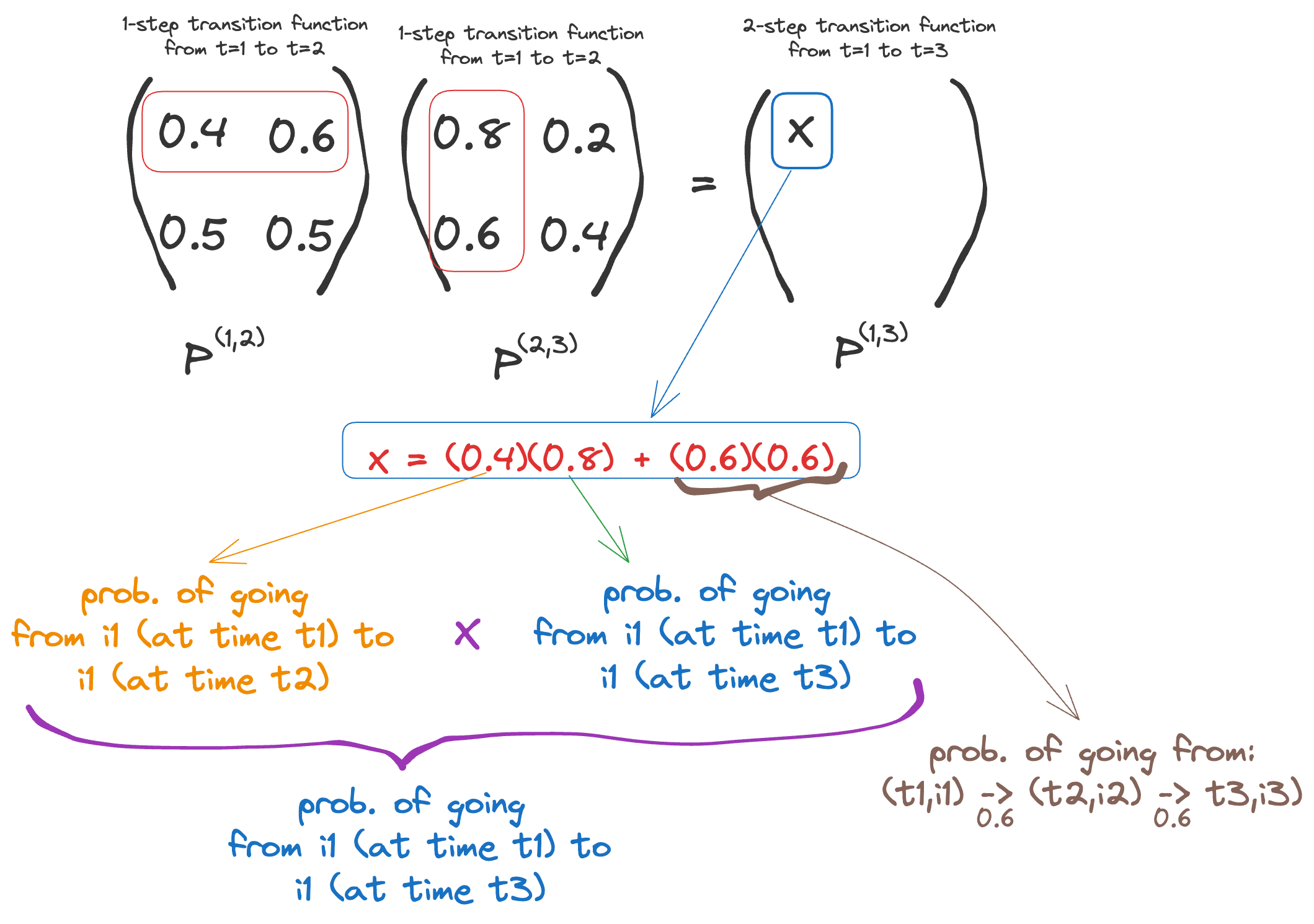
The proof is quite simple (basic conditional probability) and can be found here.