Randomised Algorithms and Order Statistics
As an example of randomized algorithms, we shall analyze the time complexity of quicksort in detail (for both cases: fixed pivot and random pivot).
Quicksort is a classic divide-and-conquer sorting algorithm proposed by C.A.R. Hoare in 1961. It sorts “in place” and is very fast in practice as it makes use of locality of reference (caching on modern processors).
The algorithm for quicksort is described as such:
- Divide: Partition the array into 2 subarrays around a pivot such that elements in lower subarray elements in upper subarray. This is done by comparing each element with the pivot and performing swaps as necessary. It takes time to partition an array of elements since exactly comparisons are performed (i.e, comparing each element with the pivot).
- Conquer: Recursively sort the 2 subarrays
- Combine: Trivial.
There are different variants of quicksort: one that uses a fixed pivot (say the first element as the pivot) and another that uniformly at random picks an element as the pivot. We shall discuss both versions separately but it is important to note the difference:
- In the case of fixed pivot, there is no randomness inherent in the algorithm. Given the same input, the algorithm executes exactly in the same manner every time it is run. Here, the randomness lies in the distribution of the input. So, we talk about average case analysis which describes the behaviour of the algorithm over all possible inputs, assuming each of the input permutations are equally likely. Note that this version is NOT a randomised algorithm.
- In the case of random pivot, even for the same input, the algorithm can execute differently each time it is run. This means that we don’t have to consider the randomness of the input, since randomness is now transferred to be within the algorithm itself. Any input can be “good” or “bad” depending on the choice of pivot for that particular run of the algorithm (so there’s no point talking about the input distribution). In such cases, we are interested in calculating the expected running time, i.e., how long our algorithm takes on average, given any input (might even be fixed input - doesn’t matter).
It is important to understand where the randomness lies.
Q. Why do we use often random pivots in quicksort?
Ans: Using random pivots makes quicksort insensitive to the input distribution → time taken does not depend on the initial permutation but on the choice of pivot. So, even if the inputs are not chosen uniformly at random but by an adversary, the algorithm is robust in terms of the running time since there is no “bad input” anymore.
Analysis of Fixed-Pivot QuickSort
Worst Case Analysis
Denote to be the worst case running time on an array of elements. Denote to be the average-case running time on an array of elements.
In the worst case, we always pick the smallest element (or largest element) as the pivot (e.g. quicksort trying to sort an already sorted array by picking the first element as the pivot). Then, .
This can be easily solved to give: (using arithmetic series).
So, the worst case running time of a fixed pivot quicksort algorithm is .
Average Case Analysis
Let’s now perform average-case analysis of QuickSort (this is not so trivial and the proof is quite involving).
Our analysis assumes all input elements are distinct (but if duplicates exist, we can use 3-way partitioning to improve the running time too).
First, given an inpiut array size of , how many possible inputs are there? Well, infinite! Because there are infinite numbers!
But we observe that the execution of quicksort does not depend on the absolute numbers themselves but on the relative ordering of numbers within the array. In particular, if denotes the smallest element of the input array , then the execution of quicksort depends upon the permutation of and not on the values taken by the . For example, the 2 arrays below will have the same execution steps of quicksort since their permutation of is the same.

Since we’re dealing with average running time, we need to have some assumption about the distribution of possible inputs. In our case, we define the average running time for quicksort on input of size to be the expected running time when the input is chosen uniformly at random from the set of all permutations (of ), i.e., the expectation is over the random choices of the input.
In other words, , where is the time complexity (or number of comparisons) when the input permutation is .
We define to be the set of all those permutations of that begin with . Clearly each set of all permutations, and for each . This means that the form a partition of the input space.
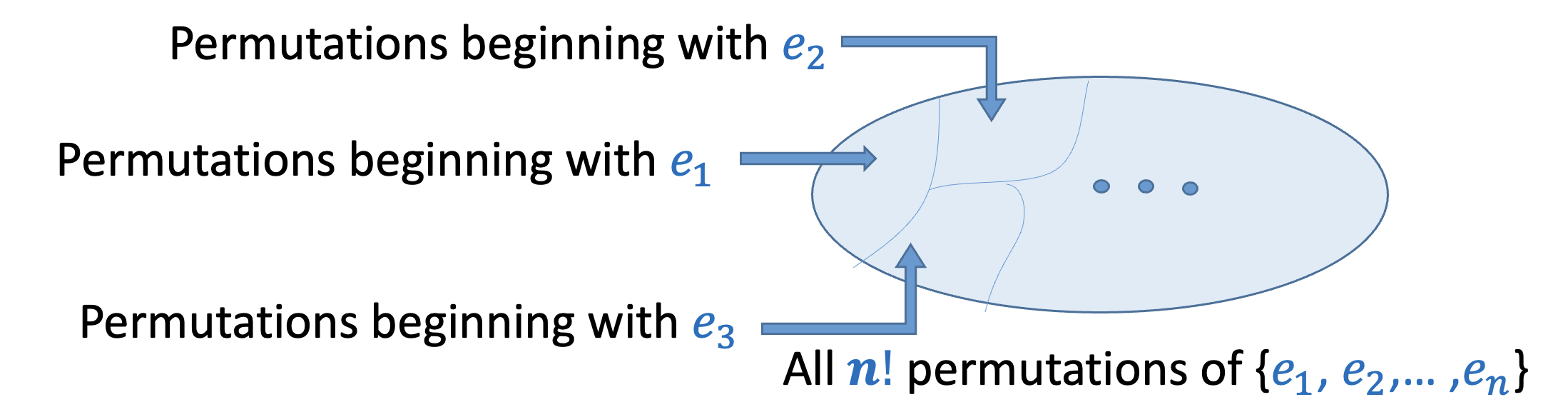
Since each of the permutations are equally likely, the size of each of the is also the same and equal to . So, each constitutes of all the permutations of the total input space.
We define to be the average running time of QuickSort over . Clearly, (that is, the average running time over all inputs, is the average of the average running time for each group of permutations (since each is equally likely). We can prove this formally as such:
Observe that
Now,
Now, we need to derive an expression for . For this purpose, we need to have a closer look at the execution of QuickSort over
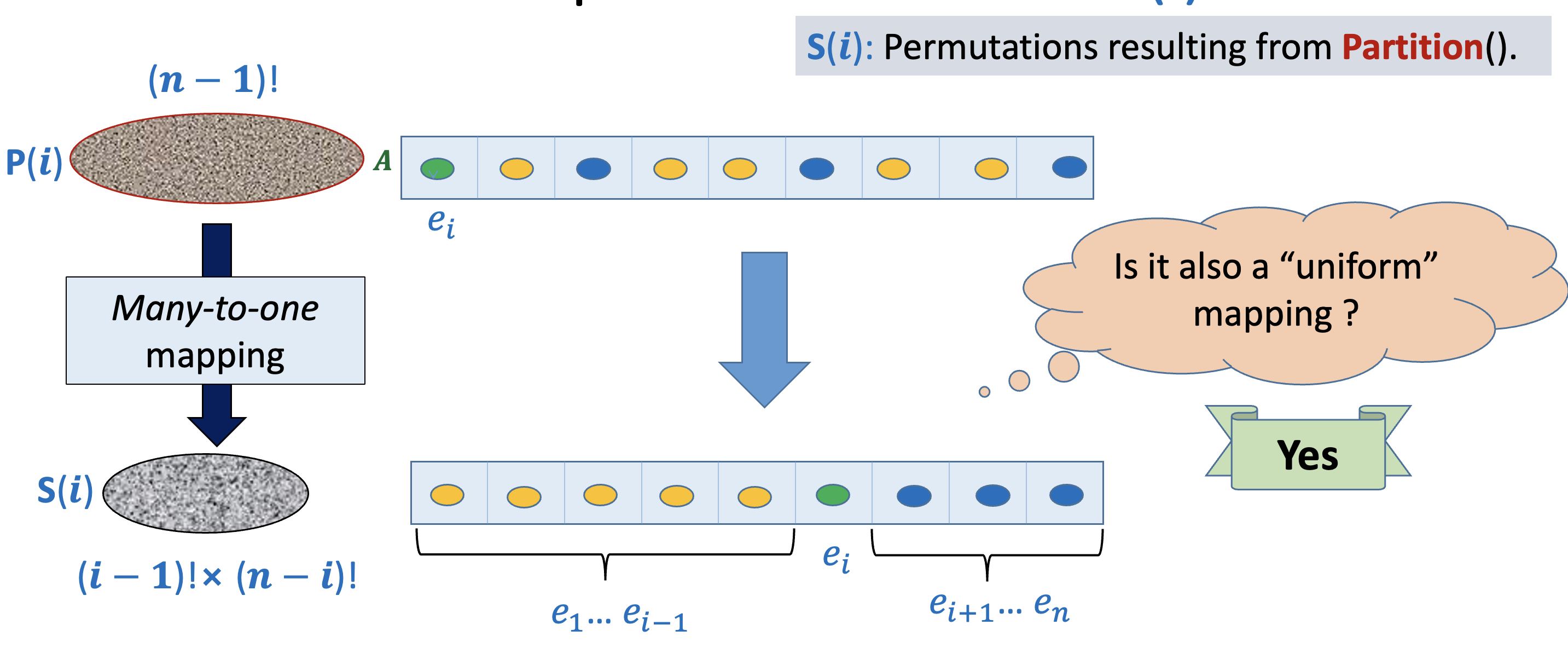
We define to be the set of all possible permutations of after partitioning takes place on an input from
Consider what happens after partitioning on an input from . There will be elements less than the pivot that will be placed in the first i positions and the remaining elements will be placed after the pivot. It should be obvous that the number of permutations possible after partitioning is less than the number of input permutations (since we’re imposing more constraints and decreasing the entropy of the space). In particular, there are permutations.
Observe that many different input permutations will give rie to the same permutation after partitioning takes place. The real question now is: Are the number of permutations that map to a single permutation after partitioning the same? (In a mathemetical sense, let be a function. Then, we’re interested in finding out whether for each , whether the size of is the same) This is called a uniform mapping.
And the answer is yes! There’s no reason why some permutations will have more preimages than other because each input permutation in is chosen uniformly at random (equally likely). In fact, there are exactly permutations from that get mapped to a single permutation in (why? 🤔)
Recall that is the average running time of QuickSort over . Then, (The last term comes because we perform exactly comparisons in the partitioning steps, comparing each element with the pivot )
We have already seen that
So, . We observe that each of the will appear twice in the sum → once from the first term, once from the second term (e.g. will appear when as well as when ).
So, (We removed the out of the summation, since it is added times, but then divided by )
Multiplying both sides by , we get:
We don’t know how to solve the above recurrence relation easily, but we can try to get rid of the summation and proceed from there.
We know that this must hold true for any value of . In particular, the same recurrence relation should also be true for . So,
Subtracting equation and , we get: (since all other terms in the summation get cancelled).
We can rewrite this in the following form using partial fractions (so that we can apply the telescoping method later):
We expand the series using telescoping method as such:
Summing up all the above equations (and splitting each term of the form to be so that one of them cancels out with the other negative term), we get:
Obviously (it takes comparisons to sort an array of size )
So, we have: .
Then adding and subtracting to get the harmonic series form:
Factoring out the from the series,
This gives us the harmonic series, and so,
where is the harmonic series up to terms.
Multiplying both sides by ,
And we know that where is the Euler-Mascheroni constant.
Substituting the exact values, we find that .
We care about the constant in this case because we want to show that the constant factor is not very large, hence, QuickSort is fast.
QuickSort vs. MergeSort
QuickSort is still the most preferred algorithm in practice. This is because of the overhead of copying the array in MergeSort (to perform the merging operation) and higher frequency of cache misses in case of MergeSort.
What makes QuickSort popular is that as increases, the chances of deviation from average case decreases (which means that it performs close to average-case with very high probability as increases). Hence, the reliability of QuickSort increases as increases.
However, there is a strong assumption here: the input permutations must be random for QuickSort to be reliably fast. In other words, Fixed Pivot QuickSort is distribution sensitive, i.e., time taken depends on the initial input permutation (not just input size!).
Oftentimes, real data is not random and it’ll be quite unfortunate if QuickSort performs in on real data. So, we face a difficult question: can we make QuickSort distribution-insensitive?
And, the answer is YES! We’ll take a look at how to achieve this next.
Analysis of Random-Pivot QuickSort
We have seen that using a fixed pivot makes the running time dependent on the input permutation, which can be set by an adversary. Our goal by using a randomised version of QuickSort is to be able to guarantee an expected running time of regardless of the input permutation. In some sense, we are transferring the randomness from the choice of input to the choice of pivot, which is internal to the algorithm.
This is necessary because often, real data is not random → suppose we have a nearly sorted array, then if we naively pick the first element as the pivot, we might end up with time (in the case of an already sorted array).
Till now, all algorithms we’ve seen so far have been deterministic. That is, given a fixed input, the algorithm follows the same sequence of execution of instructions. Now, we’re looking at a randomised algorithm, i.e., the sequence of instructions depends not only on the input but also on some random bits, which potentially change each time the function is called or the program is run. Since the sequence of instructions executed is different each time, the output as well as the running time is a function of the random bits as well as the input chosen.
This means that some times, the output produced may be incorrect/unexpected, and some times the running time may be longer than other times.
Probability that the run time of Randomized Quick Sort exceeds the average by % is .
In particular, the probability that the run time of randomisd quicksort is double the average for is . This is a very very low probability. So, with a very high confidence/probability, we can say that QuickSort will perform well in nearly all cases.
Very often, randomised algorithms are much simpler to understand (and code!) than regular algorithms. And they’re also often much faster!
⭐ There are 2 types of randomised algorithms:
- Randomised Las Vegas Algorithms - Output is always correct, but the running time is a random variable (e.g. QuickSort, QuickSelect)
- Randomised Monte Carlo Algorithms - Output may be incorrect with some small probability, running time is deterministic (e.g. Freivald’s algorithm for matrix multiplication)
Let's revisit a familiar problem, Matrix Multiplication, to see the power (and elegance) of randomised algorithms.
Matrix Multiplication
Problem Definition: Given 3 matrices, , decide whether
Deterministic algorithm: Multiply and (which takes time) and then check equality (which takes time)
Randomised algorithm (Freivald’s algorithm): Pick a random uniformly at random, and check whether in time. We can repeat this times independently. Then, the time complexity is . It can be shown that the error probability is for any we desire, i.e., the probability that the algorithm will claim that even when they’re actually unequal is (false positive rate). Obviously, it can never have false negatives because if indeed, then for any vector , the equality will hold true and the algorithm will always output “YES” (and so it’ll be correct).
Observe that Freivald’s algorithm is very easy to code and understand, and it also has lower time complexity than the best known matrix multiplication algorithm. So, in practice, we often use it instead (when we can afford to be wrong with a very small probability and time is more important then being 100% correct).
So, Freivald’s algorithm is a randomised monte carlo algorithm.
Question: Why do we need to take ? We can take any vector of the correct dimension, i.e., right? In fact, if the elements of are chosen uniformly at random, the probability of being wrong will be even lower right?
Ans: YES! You can pick any vector . In fact, if you don’t limit yourself to only and s then the probability of false positives is much much lower. In theory and literature, we use a 0/1 vector as the probability is easier to analyse - but in practice, to increase the probability of successfully classifying an equation, we can use any range of values of (the larger the better)
Analysis of QuickSort using Balls into Bins
We’ll now start to analyse the running time of randomised quicksort by trying to understand the balls and bins experiment. Suppose there are balls and bins and each ball selects its bin uniformly at random and independent of other balls and falls into it. There are certain questions that we might have:
- What is the expected number of balls in any bin? (obviously )
- What is the expected number of balls in the heaviest bin? (You can show that if , then this is as discussed in tutorial)
- What is the probability that there is at least one empty bin? (You can use Principal of Inclusion-Exclusion here)
Note that all these have very important applications in Computer Science, especially in hashing and load balancing in distributed environments.
Le’s try to answer the third question (though we won’t since we’ll get side-tracked midway and start focusing more on QuickSort once we understand the concept behind how to solve such problems)
What is the probability that there is at least one empty bin? Well, the size of the sample space (each of the balls can go into any of the bins). Let us define the event ball falls into bin. Then,
- and are disjoint when (the ball can only go into one bin - either or but not both)
- and are independent (by the question)
- and are independent (by the question)
Then, . So, .
Then, the probability that the bin is empty:
Similarly, the probability that the and bins are empty = Probability that all balls fall into neither of those bins =
In general, the probability that a specific set of bins are empty =
Now, we try to express the event that there is at least one empty bin as the union of some events. Define bin is empty. Then, the event “there is at least one empty bin” = .
Then, we can just apply inclusion-exclusion to solve this problem! (Obviously this will give a very complicated expression - because the probability itself is not so simple to calculate - there is no other simple way of doing this)
For now, let’s look at a different question: In the execution of randomised QuickSort, what is the probability that is compared with ? We can assume that all elements are distinct (if not, break the ties arbitrarily). Recall that denotes the smallest element in the array .
Obviously we cannot explore the sample space associated with Randomised QuickSort because the sample space consists of all recursion trees (rooted binary trees on nodes). We’d have to add the probability of each recursion tree in which is compared with which is not feasible!
Instead, we’ll try to view randomised quicksort from the perspective of and . To do this, we visualize elements arranged from left to right in increasing order of values. This visualization ensures that the two subarrays which we sort recursively lie to the left and right of the pivot. In this way, we can focus on the subarray containing and easily. Note that this visualisation is just for the sake of analysis. It will be grossly wrong if you interpret this as if we are sorting an already sorted array.
Recall that during the partitioning subroutine of QuickSort, elements are only compared with the pivot. In particular, if we are partitioning an array of size , there will be exactly comparisons performed - between the pivot and each of the other elements (to decide where that element should be placed).
Also, notice that if we pick a pivot such that then after partitioning, and will be on opposite sides of the pivot and so they will never be compared.
Let denote the subarray of elements from index to (inclusive). Then, we observe that and get compared during an instance of randomised quicksort if and only if the first pivot from is either or .
Another observation (which should be trivial) is that any 2 elements are compared at most once (because after partitioning, the pivot is not included in either subarray and so, it can never be compared again - which makes sense since it’s absolute position in the sorted array is already fixed so there’s no point in comparing it to other elements after partitioning anyway)
We define first pivot element selected from during randomised quicksort is and we define first pivot element selected from during randomised quicksort is . Then, (as we’ve seen), and get compared
Obviously and are disjoint (since only one of and can be chosen as the first pivot in the subarray ). So, .
We’re assuming that pivots are chosen uniformly at random. There are elements in and so . Then, we have
In conclusion, and get compared. This is quite an interesting result! It suggest that:
- The probability depends upon the rank separation (how far elements are from each other in the sorted array)
- The probability does NOT depend on the size of the array
- Probability that and are compared is (which should seem obvious because there is no other way to tell which element is smaller than the other, i.e., there is no middle element that can serve as pivot to partition and
- Probability of comparison of and is (if in the first partitioning, any other pivot other than or is chosen, they will definitely be on opposite sides of the pivot and will never be compared subsequently)
Notice that the probability that 2 elements are directly compared decreases with increase in rank separation as there is an increasing chance that their ordering can be inferred by comparing each of them to any of the elements between them. This is the key intuitiion.
We’ve now found an equation for the probability of any 2 elements being compared or not. But we haven’t found the expected number of comparisons performed by QuickSort. Let’s proceed with our analysis by considering 2 similar problems:
- Balls and bins Experiment: What is the expected number of empty bins if balls are thrown into bins?
- Randomised QuickSort: What is the expected number of comparisons performed?
Both these problems are equivalent in the sense that solving one will give us an idea on how to solve the other. So, let’s start with the balls and bins problem.
We can directly apply the definition of expectation but we’ll get stuck because we cannot calculate the probability that exactly bins are empty in simple terms - due to inclusion-exclusion, the formula gets really messy. So, we need to come up with a clever idea.
Since viewing the random experiment in its entirety looks so complex, let’s take a microscopic view. Let’s focus on one particular box at a time → This is the key shift in perspective that we need to solve this problem!
We define to be a random variable as follows:
We call such variables that take only values and indicator random variables (as they indicate the presence or absence of a certain event).
Then, bin is empty bin is not empty. We already know that bin is empty.
So, .
Also observe by linearity of expectation that , where total number of empty bins.
Recall that for any 2 events (does not matter whether dependent of independent),
So, (since each of the bins have the same probability of being empty)
We solved our balls and bins problem! (observe that we found but to find the actual probability of there being at least one empty bin, we cannot escape using the messy inclusion-exclusion principle)
We return to solve our main problem of calculating the expected number of comparisons, ( is the number of comparisons). Using our newfound perspective, we view randomised quicksort from the perspective of and .
Recall that we’ve already established a key observation: and get compared during an instance of randomised quicksort if and only if the first pivot from is either or . And we’ve also seen that this probability is, and get compared.
Now, we define for any to be an indicator random variable that indicates whether and are compared during the execution of randomised quicksort. So,
Then, .
By definition of , we have: .
By linearity of exepctation,
We can rewrite the sum as: . We can add and subtract to the series (so that we get the harmonic series, whose bound we know). We get, .
Now we use the fact that where is the Euler-Mascheroni constant. We can neglect the constant since we’re looking for a bound. So, .
Let’s get a tight bound on . Using stirling’s approximation, .
Now, . We can see that is upper-bounded and lower-bounded by . In particular, .
Hence, we get
Hence, we see that in expectation, randomised QuickSort performs comparisons and hence runs in expected time complexity. Notice that we didn’t consider any kind of input here → because the input really doesn’t matter here, only the choice of pivot matters, which is randomised anyway.
There’s a subtle leap from “QuickSort performs comparisons in expectation” to “QuickSort runs in expected time” but it’s easy to see once you realise that all the time spent by QuickSort is in comparing elements (and performing swaps, but that can be consumed within the “compare” operation) and so there’s no other time spent.
We’re done with the analysis of randomised QuickSort! We’ll now look at another common problem - order statistics - and some common algorithms to solve it.
Order Statistics
Problem Definition: Given an unsorted list of elements, the order statistic is the smallest element (that element is said to have rank )
Algorithms we can use:
- Naive: Sort the array and then report the element →
It can be shown that order statistics requires beause you need to “see” each element at least once, what if you miss an element and that happened to be the required order statistic?
So, we can we do it in ? YES!
We’ll look at 2 solutions - one is a worst-case linear time algorithm, called median of medians, and the other is a randomised divide-and-conquer algorithm that takes expected time, QuickSelect.
QuickSelect
- Pick a pivot at random and partition about it (all elements on left side of pivot are less than the pivot, and all elements on the right side of the pivot are more than the pivot)
- If the position of the pivot is target rank, recurse on left half
- If the position of the pivot is target rank, recurse on right half
Each partitioning is and it can be shown that if our choice of pivot is “decent”, the algorithm runs in , which is why the expected running time is . In the worst case, say the array is already sorted and our algorithm keeps picking the first element as the pivot and our target rank is , then it will take us time.
It’s very easy to implement → the partitioning algorithm can be slightly tweaked to handle duplicates too (just have 3 regions instead of 2 → < pivot, = pivot, > pivot).
Median of Medians
Worst case time complexity:
Median of medians solves the problems of “bad pivots” from QuickSelect. Before partitioning, we ensure that our chosen pivot is “good” such that it divides the array into 2 subarrays of roughly similar sizes so that no matter which side we recurse on, our subproblem is much smaller than before.
Algorithm:
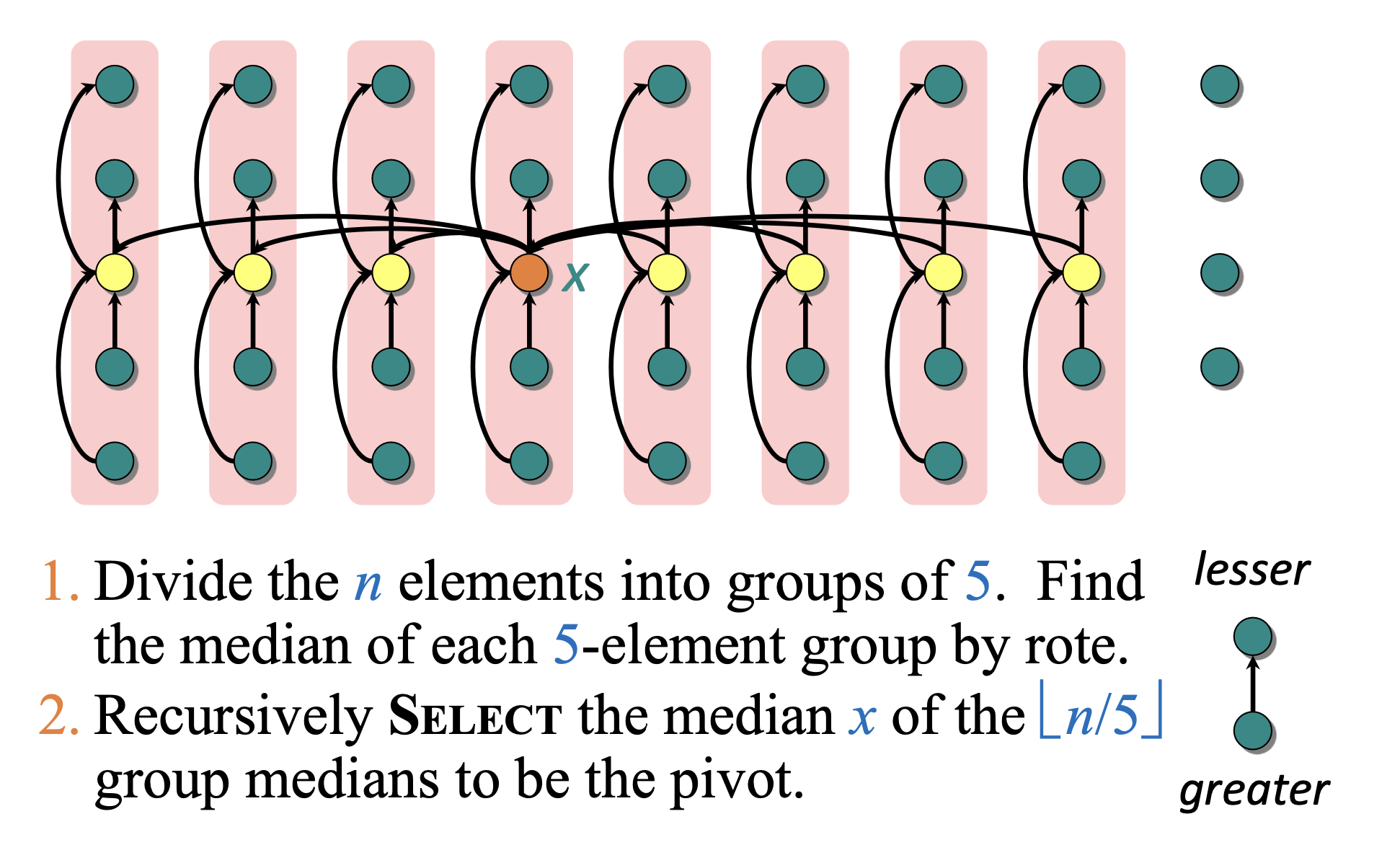
Say we’re searching for the order statistic.
- Divide the elements into groups of (Why ? Why not or ? We’ll discuss this later)
- Find the median of each 5-element group by brute force (just use
if-elseor you can even sort those 5 elements and report median) - Recursively use median of medians algorithm to find the median of the group medians to be the pivot
- Partition around the pivot . Let
- If is the target rank, return .
- If , recursively use median of medians on the left subarray
- If , recursively use median of medians on the right subarray to find the smallest element.
How can we prove that this algorithm works in ?
It’s best to visualise the size of the subarrays based on our chosen pivot:
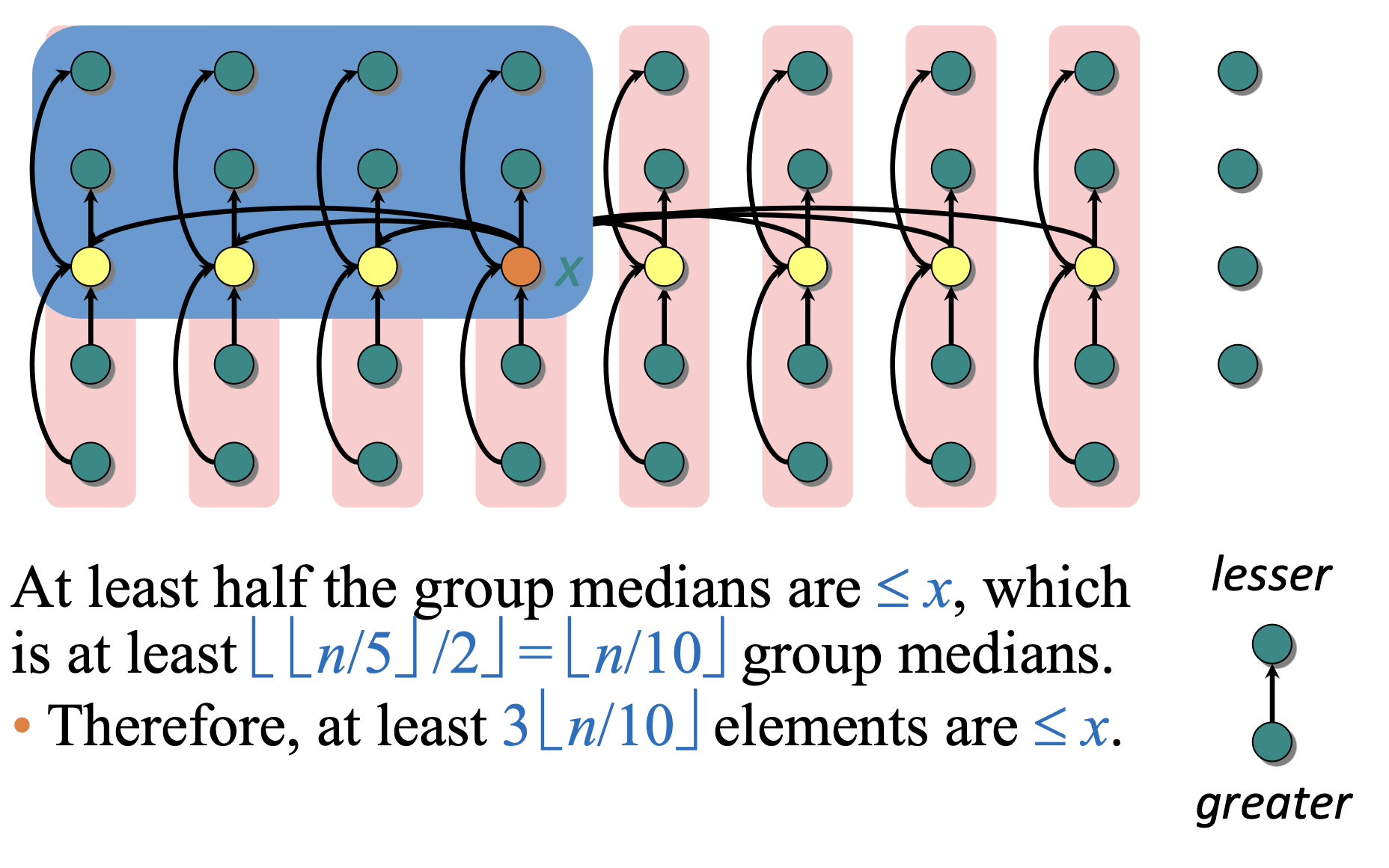
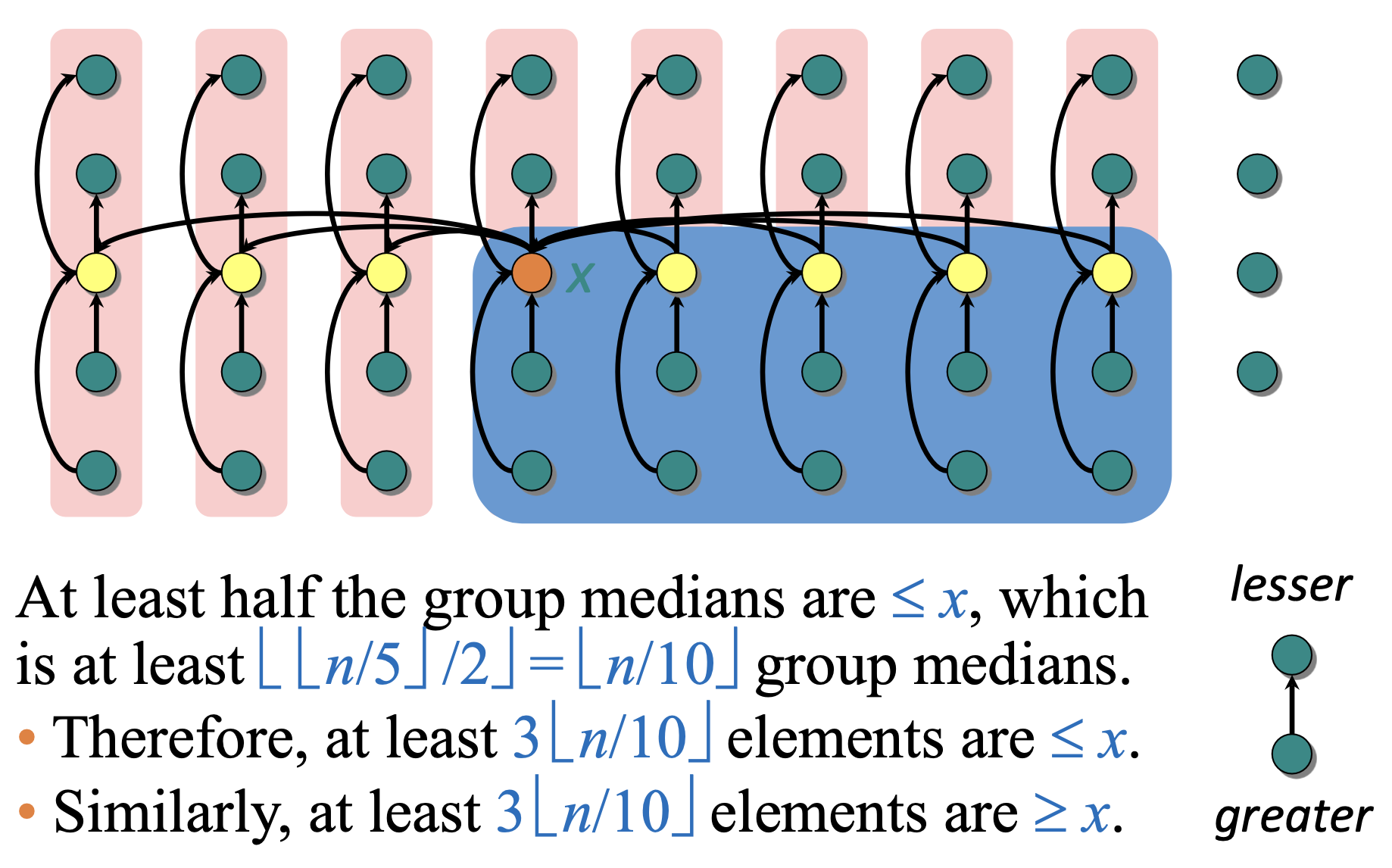
So, the size of each subarray is no more than . Since , we can write our recurrence relation as:
Explanation of the time complexity:
- Finding median of each group of is and there are such groups → which takes time in total
- We use median of medians to find the median of the group medians → which takes time
- Partitioning about the chosen pivot takes
- Recursively calling median of medians on either half - since we’re considering worst case, we always consider bigger side.
We can solve the above recurrence relation by using substitution.
After substituting we get, if our chosen is large enough to handle both as well as the initial conditions.
So, we have shown that in the worst case (notice that this is a stronger guarantee on the running time as compared to QuickSelect). In practice, this algorithm runs slowly because of the large constant factor in front of and the randomised QuickSelect algorithm is far more practical (and easier to code).
Coming back to the question of group-size of :
- Can we use a group-size of instead? No! Then the algorithm will run in as the recurrence relation becomes: , which should remind you of MergeSort (except that the halves are not equal) → notice that sum to and in general, the recurrences of this form take time.
- Can we use a group-size of instead? Yes! The algorithm will still run in time (but the constant factor may be large since you need to find the median of 7 elements by using
if-elsestatements or by sorting them)