Divide and Conquer
A Familiar Paradigm
The Divide-and-Conquer (DnC) paradigm basically consists of:
- Dividing the problem into smaller subproblems.
- Conquering the subproblems by solving them recursively.
- Combining the solutions to the subproblems into the solution for the original problem.
DnC algorithms are typically recursive, and have a recurrence relation of the form:
Here,
- is the number of subproblems generated from each problem
- is the factor by which you reduce the problem size
- is the time taken to divide the problem into subproblems and combine the solutions to the subproblems into the solution for the original problem.
DnC algorithms are everywhere. Common examples include: MergeSort, BinarySearch, QuickSort.
Although Binary Search can be implemented iteratively, it can still be seen through the lens of Divide-and-Conquer (because we are dividing the search space and hence, the problem size)
Let's look at a couple of interesting examples.
Powering a Number
Classic example of DnC.
Assumption: fit into one/constantly many words → so that multiplication is
Naive solution
To calculate , we calculate and then multiply the result by .
Recurrence relation: , which gives
But can we do better??
Optimised solution
We can make our solution more efficient by observing that we can divide into 2 parts such that we only need to make one recursive call. In particular, if is even, we can just calculate and multiply it by itself! If is odd, we can do , which still only involves a single recursive call.
So, the recurrence relation becomes: , the solution to which is: (observe that it is the same recurrence relation as binary search)
Computing Fibonacci Numbers
We can use our fast-exponentiation technique to calculate fibonacci numbers too!
But, let’s take a step back and start from scratch. We already know a method to calculate in .
We also know that has a closed form: where
Through our recently learned powering technique, we can calculate using the above formula in . But, this solution is not good in practice as floating point arithmetic is prone to rounding errors!
We make another key observation:
Then, we have the following theorem:
Matrix multiplication like this is also very similar to regular multiplication → It is since the matrix size is so we only perform operations.
So, now we use our fast-exponentation method to calculate the power of the matrix in time. This gives us a way to calculate fibonacci numbers in logarithmic time.
Matrix Multiplication
This is quite a common subroutine in many other algorithms (graph algorithms, machine learning, etc.) and so we need to try and optimise the matrix multiplication algorithm.
Problem: Given 2 matrices of compatible sizes, return their product.
The naive solution (standard algorithm based on the definition) would be:
def matrix_mult(A, B):
# assuming A, B both n x n for simplicity
C = [[0 for _ in '.'*n] for _ in '.'*n]
for i in range(n):
for j in range(n):
for k in range(n):
C[i][j] = C[i][j] + A[i][k] * B[k][j]
return C
The running time of the above code is obviously since there are 3 nested for-loops, where is the order of the matrix.
Can we do better? Let’s try using a Divide and Conquer Algorithm based on the following observation:

So, we can reduce multiplying 2 matrices, each of size , to multiplying submatrices, each of size and then performing matrix additions on those submatrices.
We know that matrix addition is since there are additions we need to perform - one for each pair of elements.
The recurrence relation is: where is the order of each input matrix. (Here, is the size of the submatrix, is the number of multiplications of submatrices, and for additions)
Using master theorem, we get → which is no improvement from the naive solution! In fact there will probably be an overhead in performing so many function calls.
We know that one way to reduce the time complexity is to reduce the number of subproblems. In this case, can we try to reduce the number of matrix multiplications on submatrices we are performing?
Strassen's Algorithm
We can reduce the number of multiplications to , by increasing the number of additions to 18 (since multiplication is what is expensive here!)
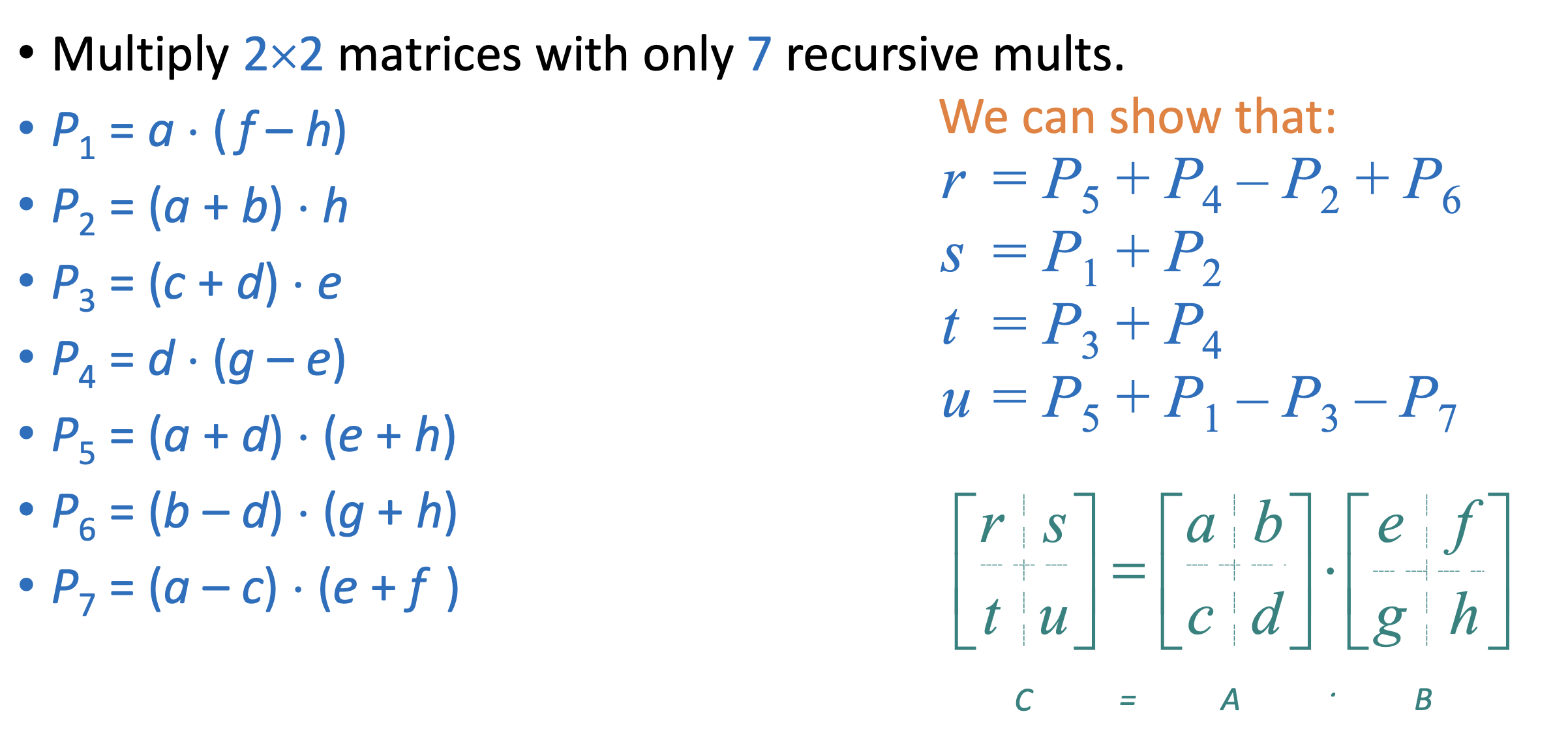
Then the recurrence relation becomes: → which gives us the time complexity
For smaller inputs like , the ordinary algorithm performs better in practice than Strassen’s algorithm (as we are ignoring the large constants in Strassen’s algorithm). So, we use the naive algorithm for as the base case. (Something like using InsertionSort as base case in MergeSort for )
Best to date matrix multiplication algorithm (of theoretical interest only): → Coppersmith-Winograd Algorithm
Recall that the asymptotic notation hides the constant factors. So, even the algorithm is slower in practice than Strassen’s algorithm. We call such algorithms galactic algorithms since they have enormous constant factors!