Hash Table
Symbol Table
A symbol table is an abstract data type that supports insert, search, delete, contains and size methods. The important thing to note here is that unlike a dictionary which supports successor or predecessor queries, a symbol table is unordered. That is, there is no ordering of keys in the data structure.
Idea 1: Implement using AVL tree
If we implement a symbol table using an AVL tree, the cost of insertion is and the cost of searching is also (Moreover, this is because it stores the key in an ordered fashion and hence it also supports successor and predecessor queries).
But what if we don’t want/need any ordering or successor/predecessor queries? Is it possible to sacrifice the ordering to gain some extra speed in insertion and searching? YES!
Our aim is to implement a symbol table with cost of insertion and cost of searching .
It is a well-known fact that any comparison based sorting algorithm requires at least comparisons. Furthermore, the fastest searching algorithms (eg. binary search) require at least comparisons. So, how is it possible to achieve for insertion and searching?? Simple - we don’t use comparison based operations (at least not directly - i.e., we don’t directly compare the elements, we compare based on their hashes 😅).
Idea 2: Use a direct access table
The idea is to use a direct access table indexed by the keys.
For example, if you wanted to store (4, Devansh) in the table, it would be stored at index 4 of the array/table.
Problems:
- Too much space (in particular, if keys are integers, then the table size > 4 billion)
- How would you store non integral values?
Solution: Use a hash function
We use hash functions to map a huge possible number of keys (out of which we have actual keys) to number of buckets.(You don’t know which keys are going to be inserted, and new keys can be inserted, old keys can be deleted, etc.)
So, we define a hash function where is the universe of possible keys (the permissible keys). We store the key in the bucket .
Time complexity for insertion: Time to compute + Time to access bucket. If we assume that a hash function has computational time, then we can achieve insertion in
Simple Uniform Hashing Assumption (SUHA)
- Every key is equally likely to map to every bucket.
- Keys are mapped independently of previously mapped keys.
Question
Why don’t we just insert each key into a random bucket, i.e., why do we need a specific hash function at all?
Answer: Because then searching would be very very slow. How would you find the item when you need it? You would have to search through all the buckets to find the item. This would take time, where = size of the hash table (i.e., number of buckets you have).
We say that 2 distinct keys collide if .
By pigeonhole principle, it is impossible to choose a hash function that guarantees 0 collisions (Since the size of the universe of keys is much larger than )
So, how do we handle collisions? There are 2 popular approaches: chaining and open addressing, each has its pros and cons.
Chaining
Each bucket contains a linked list of items. So, all the keys that collide at a particular value are all inserted into the same bucket.
How does this affect the running time of insert? No change! Still to compute hash function + to add it to the front of the linked list. This is if we assume that we are not checking for duplicate keys while inserting.
How does this affect the running time of search? Well, now once we find the bucket in time using the hash function, we may need to traverse the entire linked list to find the key. So, it can take up to , which is in the worst case (when all the inserted keys collide into the same bucket - as obviously intended by the adversary who is running your program)
Similarly, deletion also takes time.
Question
Imagine that we implement a symbol table using a single-ended Queue as the data structure. What would be the worst-case time complexities of insert, delete and search operations? (Assume we do not try to insert duplicate keys. You can only access the queue using standard queue operations, e.g., enqueue and dequeue.)
Answer: Insertion takes , Search and Deletion takes
Question
Assume that we're using a hash function to map keys to their respective positions in the symbol table. The time complexity for computing the hash is O(b) for an input key of size b while array access and comparing keys is constant time complexity. Assuming collisions are resolved by chaining linked lists and m elements are present in the table, and assuming there are never duplicate values inserted, what is the worst-case time complexity of insert and search operations on keys containing n bits?
Answer: Insertion , Search
Load
The load of a hash table is the expected number of items per bucket. If we assume that we have items and buckets then,
So, Expected Search Time = + Expected number of items per bucket (Assuming it takes for hash function computation and array access)
Let us calculate the expected search time in such a case.
Let be a random variable defined by:
We define the random variable in this way so that for any bucket , gives us the number of items in that bucket.
for any value of . This is simply because there are possible buckets for any item and each can be picked with equal probability.
.
So, expected number of items in bucket would be:
. (Each item contributes to the bucket it is in).
Hence, Expected Search Time = + . (So, we take buckets, eg. )
(But it is important to realise that the worst-case search time (not expected running time!) is still ).
Question
What if you insert elements in your hash table which has buckets. What is the expected maximum cost?
Answer: This is like throwing balls into bins. The expected maximum number of balls in a bin is . Actually, a tighter bound would be → it’s not that trivial to prove.
Open Addressing
Properties:
- No linked lists!
- All data is stored directly in the table
- One item per slot
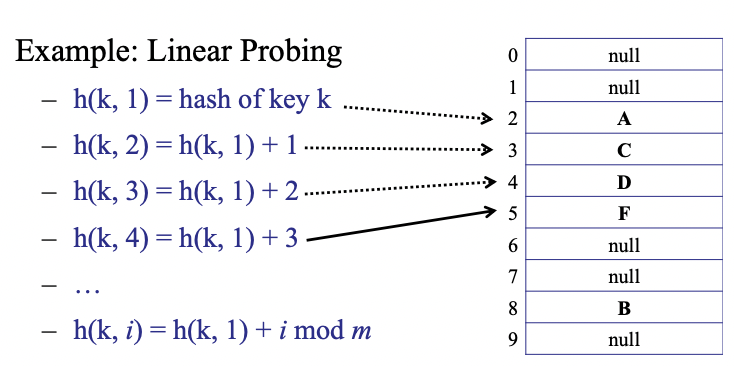
Logic: On collision, probe a sequence (deterministic) of buckets until you find an empty one
Example of a probe sequence: linear probing: (if is taken, then look at bucket and so on, until you find a bucket that is empty)
So now for this we need to have a new hash function,
where the item to map, the number of collisions encountered so far
Sample Code
This code is for any kind of probing, not just linear probing.
Inserting a key:
hash-insert(key, data) {
int i = 1;
while (i <= m) {
int bucket = h(key, i);
if (T[bucket] == null) { // Found an empty bucket
T[bucket] = {key, data}; // Insertion
return success;
}
i++;
}
throw new TableFullException(); // you visited every bucket and checked that it was full :(
}
Searching for a key:
hash-search(key) {
int i = 1;
while (i <= m) {
int bucket = h(key, i);
if (T[bucket] == null) // Empty bucket! If this is empty, we know that the key cannot be
// after this because it would have come here during the probe sequence
return key-not-found;
if (T[bucket].key == key) // Full bucket
return T[bucket].data;
i++;
}
return key-not-found; // Exhausted entire table
}
Deleting a Key
If you just remove the key from the table and set it to null, during search, the hash-search function may return key-not-found even if the key exists (because of the “gap” in the probe sequence).
Simple solution: Don’t set the value to null on deletion, set it to DELETED to indicate that the slot is empty now but there was an element here before.
If you encounter a DELETED value while probing for a bucket to insert, you can feel free to insert the new item there (because DELETED is just a placeholder that can be safely overwritten)
Hash Functions
2 Properties of a good hash function:
- enumerates all possible buckets as iterates from to (So that you only return
TableFullException()when the table is actually full and you have made sure that there are no empty slots).- For every key , and for every bucket
- The hash function is a permutation of
- Uniform Hashing Assumption (UHA) - Every key is equally likely to be mapped to every permutation, independent of every other key. (There are permutations for a probe sequence, where table size.
Note that Linear Probing satisfies the first property but does not satisfy the second property! (For example, it is impossible to find a key such that its hash generates the permutation for a table of size 3. This is because the only possible permutations generated by the linear probing sequence is or or )
Problem with Linear Probing: Clusters
If there is a cluster (when a lot of elements are placed in contiguous buckets), there is a higher probability that the next will hit the cluster. Because if hits the cluster (any bucket in the cluster), the cluster grows bigger as the item gets added to the end of the cluster. This is an example of “rich get richer”.
If the table is full, there will be clusters of . This ruins constant-time performance for searching and inserting.
But, in practice linear probing is very fast! Why?
Because of caching! It is cheap to access nearby array cells (since the entire block containing a lot of contiguous array cells is loaded into the main memory). For example, if you want to access A[17], the cache loads A[10...50]. Then, it takes almost 0 cost to access any cells in that range. Recall that block transfer time is far far more than memory access time.
So, even though there will be clusters of when the table is full, the cache may hold the entire cluster. So, this makes linear probing no worse than a wacky probe sequence that circumvents the issue of clusters.
Good hashing functions
We saw that linear probing does not meet the second criteria of a good hash function, i.e., it does not satisfy UHA. So, the question is: How do we get a good hash function that satisfies UHA? Double hashing of course!
Start with 2 ordinary hash functions satisfying SUHA:
Define a new hash function:
Since is pretty good, is “almost random”.
Since is pretty good, the probe sequence becomes “almost random” (we just added some “noise” to the value to increase randomness). (we need to in the end so that we get a value between and and we can map it to a bucket of table size .)
Claim: if is relatively prime (co-prime) to , then hits all buckets (i.e., it generates a permutation of .
Proof: Suppose not. Then for some distinct (since it does not hit all buckets then there must be two equal values of for two distinct - by Pigeonhole Principle):
Example: If , then choose to be odd for all keys .
Performance of Open Addressing
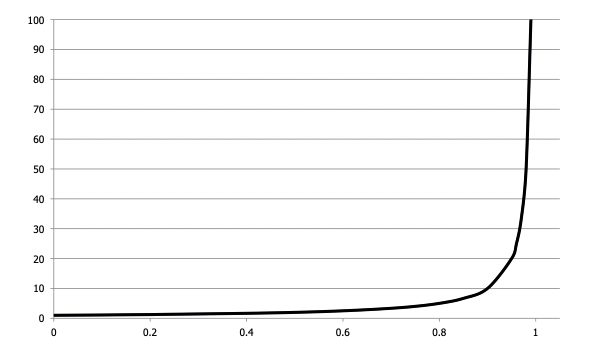
Let Load . Assume (the table is not full)
Claim: For items, in a table of size , assuming uniform hashing, the expected cost of an operation (insert, search, delete) is: .
Example: if , then .
Proof of Claim:
Say, you have already inserted items and you want to insert the next element .
The probability that the first bucket you find (i.e., ) is full is . Then, the probability that the second bucket is full given that the first bucket is also full is . So, you need to probe again: probability that the third bucket is also full given that the first two are full: and so on..
Expected cost:
Note: . (only when ). For example, )
Therfore, expected cost is
If , the expected cost of searching in a hash table using open addressing is . Is this true or false?
False. Let . Then so it will take to search for an item in a hash table with items and buckets. Moreover, we know that when we use linear probing and even if the table is quarter full, we will have clusters of size in expectation. So, the cost of searching in a hash table using open addressing is at least .
You are only allowed to use under the assumption of UHA. Linear probing, quadratic probing, etc. do not satisfy UHA and you cannot use this time complexity!
If (table size) is prime, and , only then we can guarantee that quadratic probing hits all the buckets in the table. Sometimes, it is possible that quadratic probing finds an empty slot in the table after tries too (which is why some people wait for a longer time before they return a tableFullException().
Summary of Open Addressing
Advantages:
- Saves space - Empty slots vs linked lists (in chaining)
- Rarely allocate memory (only during table resizing) - no new list-node allocations
- Better cache performance - table all in one place in memory. Fewer accesses to bring the table into cache. Linked lists can wander all over memory.
Disadvantages:
- More sensitive to choice of hash function: clustering is a common problem in case of linear probing
- More sensitive to load (than chaining) - performance degrades very badly as
Resizing the Table
Throughout this discussion of table resizing, assume that we are using hashing with chaining and our hash function obeys simple uniform hashing (although this is a false assumption - it can never be true in practice)
We know that the expected search time is .
So, the optimal size of the table is .
The problem is we don’t know in advance. If , then there’s a possibility of too many collisions, and if , there’s too much wasted space (of course the numbers 2 and 10 here are arbitrary but it provides some intuition as to why we need to grow and shrink our table size as new elements are added and old elements are deleted from the table).
Idea: Start with a small constant table size. Grow and shrink the table as necessary.
- Choose a new table size
- Choose a new hash function (Why do we need a new hash function? Because the hash function depends on the table size! . Java hides this by doing the hashing itself)
- For each item in the old hash table, compute the new hash function and copy item to the new bucket.
How much time would this take? Well, it takes to access buckets. In each of the buckets, we need to access the elements themselves. There are elements. So, it takes elements for that. ALSO, allocating memory takes time proportional to the memory size being allocated. That is, if you initialise a large array, that takes some time. So, to allocate a table of size , it takes .
Hence, the total time to grow/shrink the table is .
But... How much should we grow by? When should we grow?
Idea 1: Increment table size by 1
This is a ridiculously bad idea because each time you add a new element, you need to create an entirely new table. This takes too much time (in particular, the total time for inserting items would be ) This is because you are thinking short-term and each time you insert after growing the table, the table becomes full again. So, when you insert again, you need to resize.
Note that this is also true for incrementing the table size by a constant number (i.e., will also take for large values of no matter how large is). Unfortunately, even seasoned software engineers write code that grows the table size by a constant factor like 1000, forgetting that it is still a bad design decision which leads to complexity.
Idea 2: Double table size
if (when the table is full, create a new table whose size is double - so there is sufficient space for insertions to occur)
Then, you perform expansions only times while inserting items. So, the total cost of inserting items is .
For example, let your initial table size be 8 (it’s always good practice to keep your table size a power of 2). Then, the cost of resizing is:
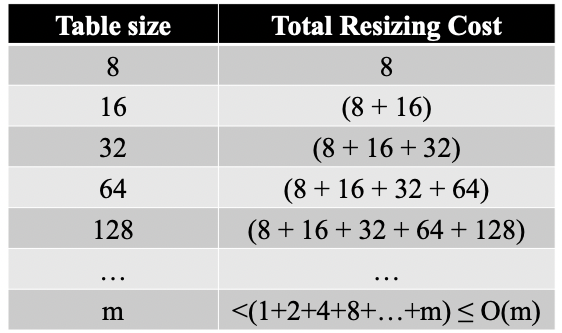
Cost of resize:
Cost of inserting items + resizing:
Most insertions take time (since no resize is required). Some insertions are expensive (linear cost).
The average cost per operation is . In fact, the amortized cost of insertion is - think of depositing each time you insert an element, with each insert operation itself costing . You use the additional to grow the table size (assuming growing to a size requires and so, each element needs to have to contribute to the expansion process). Observe that you are growing the table only after filling it completely and so you are sure that you have added new items before the next growth occurs (assuming current table size is ). Similarly for deletion, deposit for each delete operation: to fund the delete operation and for future shrink operations. So, each operation requires a constant amount of money and hence is amortized .
Idea 3: Squaring table size
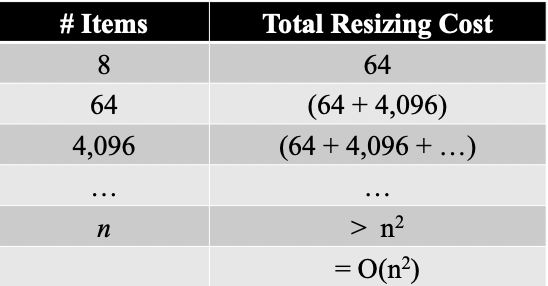
If doubling table size is good, squaring table size must be better right? Well, no. not really. In fact, it is . This is because you’re allocating toooo much memory at each resize. For example, if your table size is 64 and you insert the 65th element, the table size grows to 64*64 = 4096!
Each resize takes time. So, average cost of each operation is
Shrinking Table
When the table becomes too big, we need to shrink the table. Again, the question is: When do we shrink?
Attempt 1
if (grow) and if (shrink).
This is actually a really bad idea! Consider the following problem:

You might have to resize at every insertion and deletion
Attempt 2
If (grow when the table is full)
If (shrink when the table is less than a quarter full so that when you half the size, there is still sufficient space for insertions to be performed)
Claim (very important invariants that you should be able to observe for any kind of growth/shrink rules given):
- Every time you double a table of size , at least new items were added (after your previous grow/shrink operation)
- Every time you shrink a table of size , at least items were deleted. (after your previous grow/shrink operation)
These two claims can be easily proven by observation.
By analysing the amortized time complexity, we find that insertion and deletion both take amortized.
Note that search takes expected time (not amortized!)
- Insertions and deletions are amortized because of table resizing (i.e., an insertion/deletion algorithm can trigger a table resize once in a while - which is expensive)
- Inserts are not randomized (because we are not searching for duplicates)
- Searches are expected (because of randomization of length of chains in each bucket) and not amortized (since no table resizing on a search)